
1.老师留的作业是用scrapy爬动态网页天猫商品的价格,但是用Chrome每次点开网页的时候都会弹出登录界面,虽然不影响爬取价格,但是想把这个页面关闭 网页:https://detail.tmall.com/item.htm?id=555358967936
2.代码:
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
driver = spider.drive
driver.get(request.url)
# driver.switch_to.frame("sufei-dialog-content")
#因为网页需要时间渲染,在这里确定目标元素
locator = (By.XPATH, '//span[@class="tm-price"]')
close_btn = (By.XPATH,'//div[@class="sufei-dialog-content"]/div[@id="sufei-dialog-close"]')
# driver.switch_to.frame("sufei-dialog-content")
WebDriverWait(driver, 3,1).until(EC.presence_of_element_located(close_btn))
# driver.switch_to.frame("sufei-dialog-content")
click = driver.find_element_by_xpath('//div[@class="sufei-dialog-close"]')
actionchain = action_chains.ActionChains(driver)
actionchain.click(click)
actionchain.perform()
print('点击已结束')
driver.switch_to.default_content()
# driver.switch_to.parent_frame()
#等待网页渲染,最多等待15s,并且每1s查看一次是否出现目标元素
WebDriverWait(driver, 15, 1).until(EC.presence_of_element_located(locator))
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
#返回请求网页后得到的源代码
return HtmlResponse(url=request.url,body=driver.page_source,request=request,encoding='utf-8',status=200)
_3.我尝试过分析可能是iframe的问题,但是尝试过后总是提醒
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//div[@class="sufei-dialog-close"]"}
(Session info: chrome=75.0.3770.80)
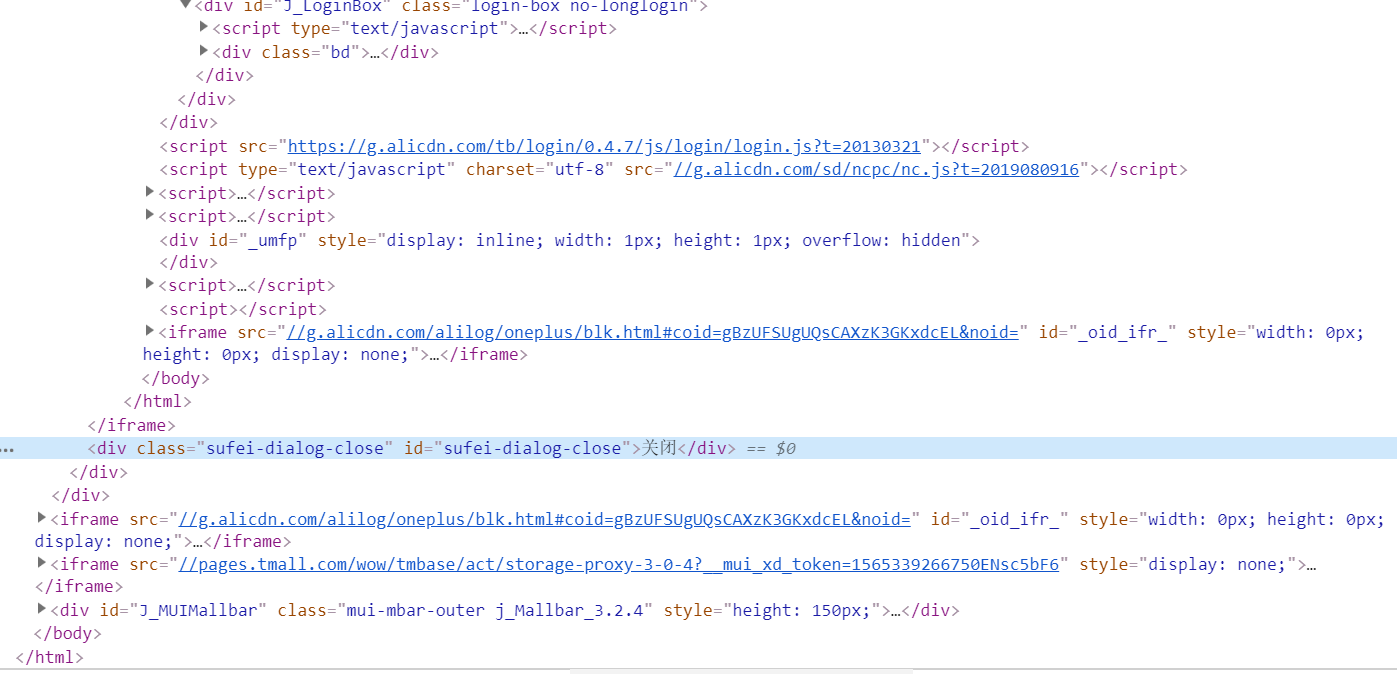
蓝色的就是想要关闭的标签
感谢帮助(●'◡'●)





