关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
莫あ缘お
2022-05-21 23:12
采纳率: 100%
浏览 30
首页
Python
已结题
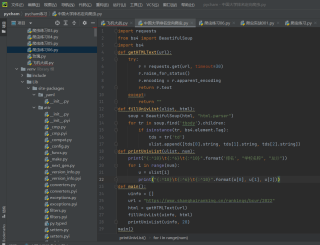
学爬虫遇到这个问题如何解决?
python
这个如何解决,有知道怎么解决的么? 看了半天我也没看明白哪里出错了,
顿时不知所措😭
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
二九筒
2022-05-23 11:28
关注
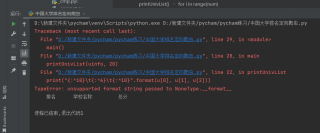
format后面参数没有取到值是空的,none类型,所以会报错
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
-
解决
爬虫
中
遇到
的js加密
问题
2019-08-10 07:40
总结,
解决
Python
爬虫
中的JS加密
问题
需要深入理解JavaScript加密原理,借助各种工具和库进行逆向解析和模拟执行。通过不断实践和
学
习,我们可以克服这些挑战,成功获取到所需的数据。在实际操作中,应遵循合法、道德...
Python
爬虫
教程:反爬
爬虫
经常
遇到
的
问题
及
解决
方法
2025-02-14 09:15
WANGWUSAN66的博客
字体来反爬猫眼口碑,左面写的口碑9.2,检查之后,右面根本不会显示该数字,而是显示几个方框在无痕模式准备抓包,打开网址,可以找到它的数字就像一段乱码,这就是它自定义的字体:处理方法:我们可以将数字和...
爬虫
代码实例源码大全+
Python
爬虫
Scrapy课件源码.zip
2024-03-27 03:27
"项目说明.zip"可能是对整个
学
习资源包的详细说明,包含了如何使用这些资料、各个文件的功能介绍以及可能
遇到
的
问题
和
解决
方法。 总的来说,这个资源包为
Python
Scrapy的
学
习提供了丰富的实践材料。通过
学
习和实践...
爬虫
可以做什么?
Python
爬虫
入门必看保姆级教程!(
学
习资源+
学
习路线)
2024-08-26 13:41
豆本-豆豆奶的博客
Python
爬虫
,也称为
Python
网络
爬虫
或网页蜘蛛,...
Python
爬虫
的工作原理可以大致分为以下几个步骤:1.发起请求:使用
Python
的HTTP库(如requests库)向目标网站发起请求,发送一个包含请求头、请求体等信息的Request。
解决
Python
网页
爬虫
之中文乱码
问题
2021-01-20 04:29
最近在
学
习网页
爬虫
时就
遇到
了这样一种
问题
,中文网站爬取下来的内容往往中文显示乱码。看过我之前博客的同
学
可能知道,之前爬取的一个
学
校网页就出现了这个
问题
,但是当时并没有
解决
,这着实成了我一个心病。这不,...
python
爬虫
中采集中
遇到
的
问题
整理
2021-01-19 23:24
今天小编想就
爬虫
采集数据时
遇到
的
问题
进行一个整理,以及在
遇到
不同的
问题
时,我们应该想的是什么样的
解决
思路,具体内容如下分享给大家。 1、需要带着cookie信息访问 比如大多数的社交化软件,基本上都是需要用户...
Python
爬虫
学
习之旅:从入门到精通,要
学
多久?_
python
爬虫
自
学
要多久
2024-09-22 16:10
2401_87361571的博客
入门阶段是
学
习
Python
爬虫
的关键阶段,在这个阶段,你需要掌握
Python
的基础知识和相关的库和工具。在这个阶段,你将
学
习更高级的技术,如正则表达式、XPath和CSS选择器等,以帮助你更精确地定位和提取页面中的数据。
python
爬虫
入门到实战的
学
习顺序.pdf
2022-05-29 03:34
找到一个实际项目,如创建简单的网站或小型应用,这将帮助你巩固
Python
基础知识,并提升
解决
问题
的能力。同时,加入
Python
社区,寻找导师或同伴,他们在
遇到
困难时能提供指导,但也要
学
会独立思考和有效地搜索
解决
...
爬虫
为什么常用
Python
语言?
2024-04-25 09:03
酌沧的博客
上图是本人看过的几步
爬虫
相关的
python
书。
【
Python
爬虫
详解】第一篇:
Python
爬虫
入门指南
2025-04-20 09:15
Luck_ff0810的博客
为了应对不同的爬取需求和反爬挑战,
Python
生态系统提供了多种
爬虫
相关的库。库名特点适用场景Requests简单易用的HTTP库基础网页获取HTML/XML解析器静态网页内容提取Scrapy全功能
爬虫
框架大型
爬虫
项目Selenium浏览器...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
3月16日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
3月8日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
5月21日

 分享
分享 系统已结题
3月16日
系统已结题
3月16日 已采纳回答
3月8日
创建了问题
5月21日
已采纳回答
3月8日
创建了问题
5月21日



