本人使用springcloud+docker的结构搭建微服务,现在遇到的问题是:
docker宿主机使用-P命令随机端口绑定的docker指定端口(比如每个容器都暴露8080端口),
但是容器中无法知道宿主机的ip和映射端口,即eureka上的实例不知道暴露给外部的什么访问IP和端口(宿主机IP和宿主机port)。
请教各位大神,此问题该如何解决,谢谢!
【docker显示宿主机的随机端口32773映射了容器8080端口】

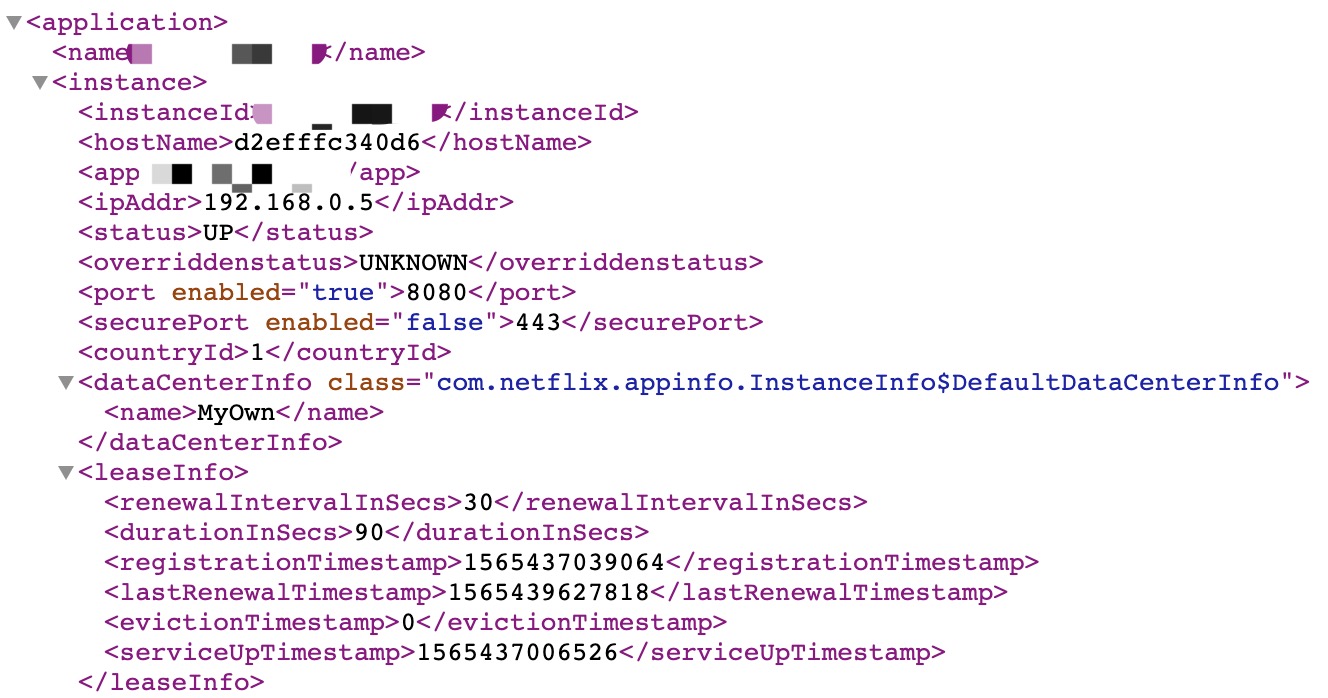
【Eureka显示是容器端口8080,而非宿主机映射端口】

本人使用springcloud+docker的结构搭建微服务,现在遇到的问题是:
docker宿主机使用-P命令随机端口绑定的docker指定端口(比如每个容器都暴露8080端口),
但是容器中无法知道宿主机的ip和映射端口,即eureka上的实例不知道暴露给外部的什么访问IP和端口(宿主机IP和宿主机port)。
请教各位大神,此问题该如何解决,谢谢!
【docker显示宿主机的随机端口32773映射了容器8080端口】
【Eureka显示是容器端口8080,而非宿主机映射端口】
 分享
分享
请问这样使用有什么问题么?容器有很多种网络模式,默认的就是你这种通过iptables转发来做映射的。你从外网访问宿主机的32773端口就行了,就相当于访问了容器的8080端口。
如果想要方便一点,直接把容器的端口开放到宿主机上,可以使用docker的hosts网络模式,具体方法可以查一下,加一个参数就行,这样容器中开放了8080端口,宿主机也就是直接开放了8080端口,且这个8080端口就是被容器所打开的。
分享




