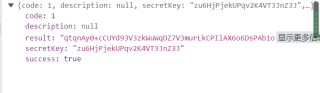
我的代码如下:
import requests
import re
#构建头部
head={"user-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}
#通用网址
urls1='https://wenshu.court.gov.cn/website/parse/rest.q4w'
#参数
params={'pageId': 'b74c0348f48323e0989104d60ecc29cb',
's38': '100',
'fymc': '北京市高级人民法院',
'sortFields': 's50:desc',
'ciphertext': '111001 1100001 1101101 1001011 1000110 1011010 1010011 1111010 110010 1001110 1001110 1110001 1000100 1001000 1101111 1010011 1111001 1001000 1110001 1000100 1100010 110111 1101111 1000100 110010 110000 110010 110010 110000 110101 110010 110010 1001011 1010011 1111010 1110000 1110110 1001110 1110011 1010101 1100101 1100111 1001001 110111 1110100 1101101 1101000 1010101 1100001 1000011 110001 1101110 110001 1110111 111101 111101',
'pageNum': '2',
'pageSize': '5',
'queryCondition':'[{"key":"s38","value":"100"}]',
'cfg': 'com.lawyee.judge.dc.parse.dto.SearchDataDsoDTO@queryDoc',
'__RequestVerificationToken': 'HIvB9LtxOIGrmoW2dCDLDP6H',
'wh': '609',
'ww': '1280',
'cs': '0',
'HifJzoc9': '4.5flpnYI0JS5iuUTSbsfetifYW2ySbwqWOHxC9kgjmQMk71ko7dZyFiriNxGl0M8jfnrAKLcNPAT6CeOWRHM2dP8iZo09JDTHD4tNmyqU6wLPlr6QdcQMoptfvy7ifjzMde_G4JxSbgvyfMVTkjwc1ycq8.p3k4W5kXLiJeq8GhgZbWCOOii2vn7Zv.ZDuoohTeZ3RsCTj_TF29nKE8ZMTi1GRyROa5Z8qHchtvuzH6SWCo_qvxw8EiAqn7Ay6.A2PupcMh9_2RgfrxO3TcJ7HA5CQcwomL.DRI92fL2.nP0EuDZmP4aBJcR1T8ICOJlrstZEouwW8iSEMOHd46Z0c27jnpCifvTvNeeMDxLOSSH2Cop5wKu7rBU_LEC0CdlhO3FdfEHCyXhgohTVDMLCbPkYGyH0owlweyeK1jnrE6BzBu2L4mdB9GjbywoVySWalZ'
}
#获取每页文本信息
req=requests.post(url=urls1,headers=head,data=params)
req=req.text
print(req)
代码运行后只能返回一个不相关的网页代码,并不能返回我想要的信息。请问该怎么解决呢?
返回的结果:
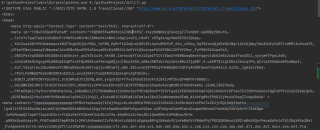
我想要的: