哈喽,我想请教一下,为啥使用lxml.etree.HTML( ),解析出来的是个空[ ],,用了BeautifulSoup也是一样,就是返回一个空,网页的html结构是可以拿到的
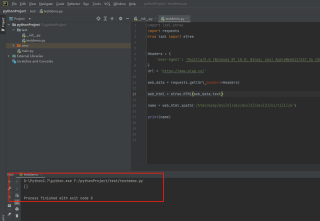

哈喽,我想请教一下,为啥使用lxml.etree.HTML( ),解析出来的是个空[ ],,用了BeautifulSoup也是一样,就是返回一个空,网页的html结构是可以拿到的
 分享
分享
先打印网页文本,看看有没有这个数据,没有就是反爬了!
分享 系统已结题
6月4日
系统已结题
6月4日 已采纳回答
5月27日
修改了问题
5月27日
创建了问题
5月27日
已采纳回答
5月27日
修改了问题
5月27日
创建了问题
5月27日

