from bs4 import BeautifulSoup
import pandas as pd
import requests
from urllib.request import urlopen
def getContent(url):
myURL = urlopen(url)
if myURL.getcode()==200:
content = myURL.read()
elif myURL.getcode()==418:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = requests.get(url, headers=headers)
content = req.text
else:
content = None
print("爬取失败!")
return None
bsObj = BeautifulSoup(content, 'lxml')
return bsObj
def getList(url):
names = []
authors = []
prices = []
bsobj = getContent(url)
if bsobj:
bs = bsobj.find_all('div', {'class': 'imgmain2_r floatleft_q'})
for i in range(0, len(bs)):
book_name = bs[i].find('p',{"style":"height:40px"}).find('a').text
author = bs[i].find('p',{"style":"height:20px"}).text.split('\n')[1]
price = bs[i].find('p',{"class":"dj_r"}).text.split(':')[1]
names.append(book_name)
authors.append(author)
prices.append(price)
return names,authors,prices
url = 'http://www.cyp.com.cn/?action-model-name-specialbooksort-itemid-3.html'
names,authors,prices = getList(url)
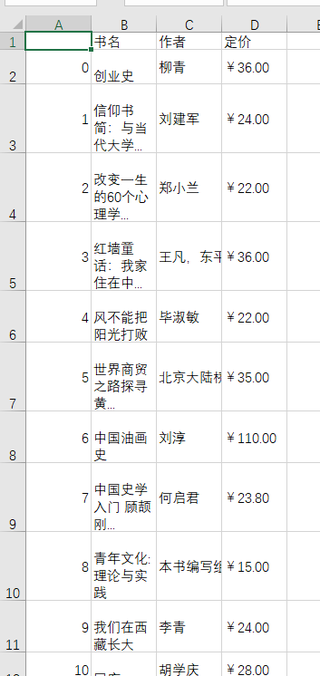
bookInfos = pd.DataFrame({'书名': names, '作者': authors, '定价':prices})
bookInfos.to_csv('pachong_XYY.csv', encoding='gbk')




 分享
分享
 系统已结题
6月16日
系统已结题
6月16日 已采纳回答
6月8日
已采纳回答
6月8日


