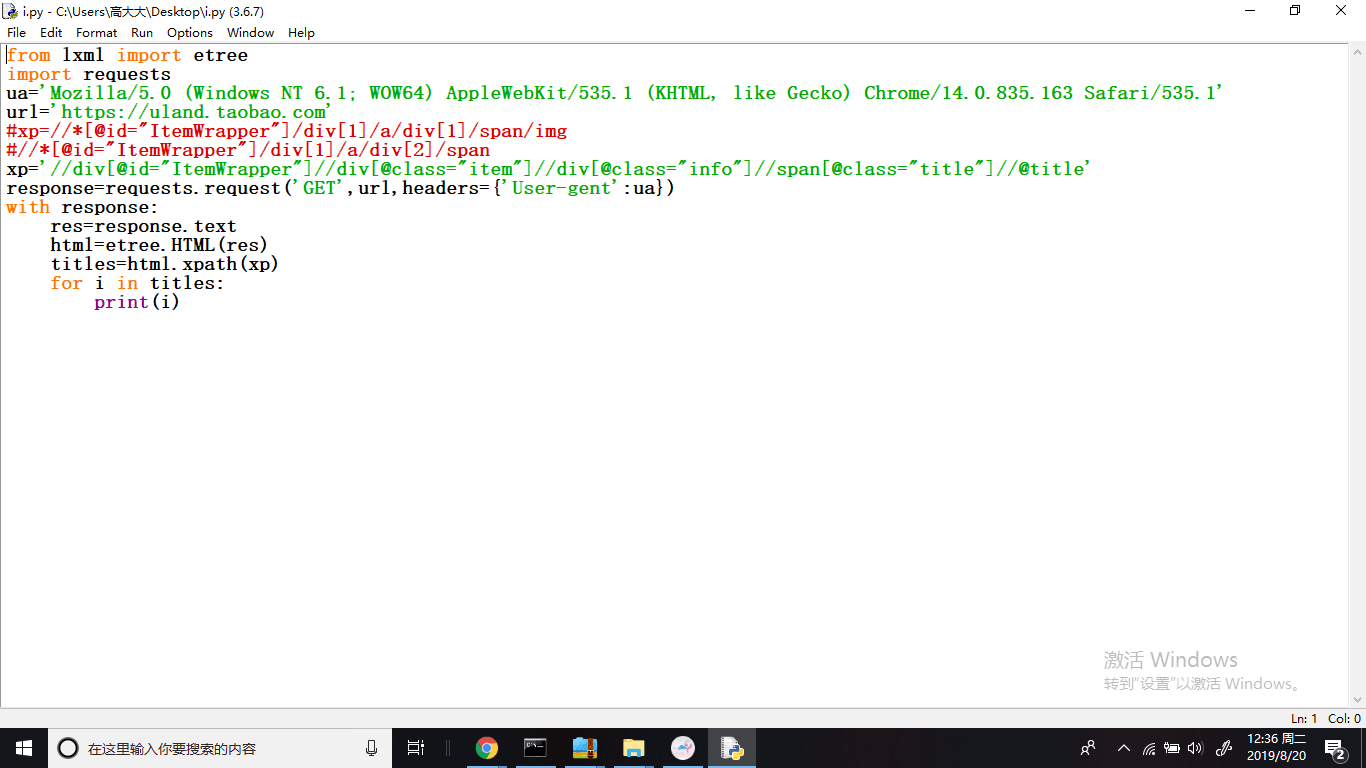
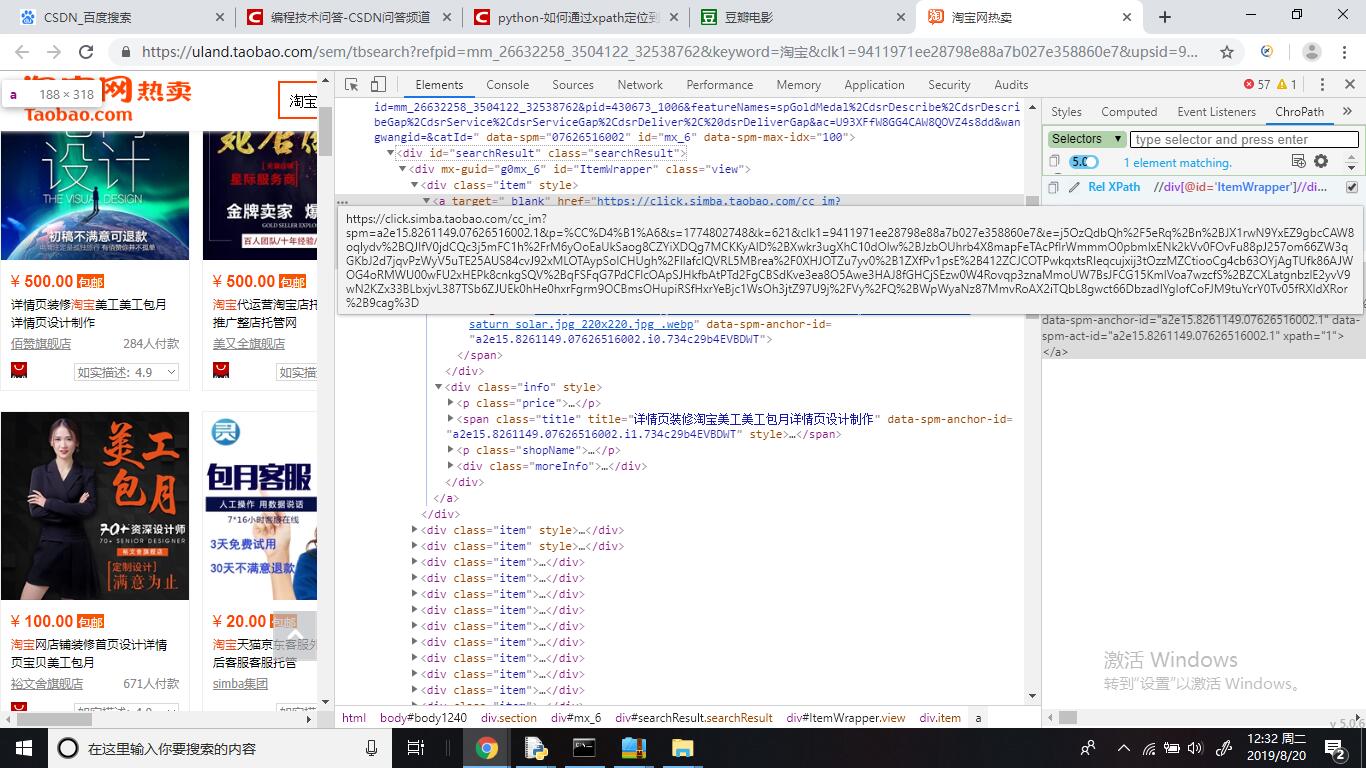

如何通过xpath定位到span标签里的title

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新

- 2020-09-18 10:38回答 1 已采纳 https://blog.csdn.net/sun_977759/article/details/100989829
- 2022-10-07 20:41回答 2 已采纳 //button[@id=‘signin-submit-button’]这个东西不是能够被识别的xpath。建议你使用Selenium IDE插件录制一下,然后把录到的路径放进去就可以了,很方便
- 2022-07-07 17:50回答 2 已采纳 这串语句你在python里面运行的?
- 2020-08-28 12:03软件测试李同学的博客 本来很简单的一个问题。就是xpath在谷歌浏览器控制台编写调试的时候,用中文的...# 通过文本内容模糊定位元素 browser.find_element_by_xpath('//span[contains(text(),"系统设置")]').click() 点击系统设置。 ...
- 2022-08-08 12:11回答 2 已采纳 原因是列表div_tag只有一项, 而变量title, piaofang有很多项。改成这样: import requests from lxml import etree import csv ur
- 2023-03-17 10:32回答 4 已采纳 https://blog.csdn.net/superwfei/art
- 2022-05-08 22:17回答 1 已采纳 //*这是个星号
- 2021-08-22 18:00better meˇ:)的博客 xpath xpath:查找XML(用来存储和传输数据的)文档的语言 lxml:专门用来处理XML和HTML数据的三方库 etree.XML():将XML格式的字符串转换成Element对象,可以方便地使用xpath方法。 etree.HTML():将HTML格式的字符...
- 2020-03-14 10:52回答 1 已采纳 有两个地方需要考虑,一个是它是不是ajax动态加载的 一个是你的xpath路径是否写对,建议你一个是使用chrome f12的xpath提取功能来提取xpath,一个是取不到的时候,先取上一层的调试
- 2022-01-24 12:19回答 2 已采纳 xpath写错了
- 2023-03-13 17:09回答 5 已采纳 titles=html.xpath('//*[@class="title"]/a//text()') abstracts=html.xpath('//*[@class="abstract"]') r
- 2020-10-16 23:28旧人小表弟的博客 有时候不能直接定位到标签的属性,需要首先定位到webelement,之后get到属性 try: temp['host_url'] = node.find_element_by_xpath('./div/div/div/ytd-video-meta-block/div/div/div/yt-formatted-string/a/@href'...
- 2023-04-04 16:31回答 1 已采纳 效果如下 问题是点击链接之后没有跳转到对应窗口所以找不到对应的XPATH这边也是写了跳转和返回的逻辑构建对象的路径还需要你这边改回来,应该对你有所帮助有用请采纳 from lxml import et
- 2021-02-20 12:42chinaherolts2008的博客 1.什么是XPath? xpath是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历,XPath 通过使用路径表达式来选取 XML 文档中的节点或者节点集。...Xpath正是通过这样的
- 2023-04-10 12:37Mcdulloo的博客 ]/ancestor::div[@class=“layout-right flex-baseline”]//div[@class=“layout-right-functional”]//button[contains(@class,“el-button”)]//span[text()=“提交作业”]//span[text()=“个人作业”]/ancestor::...
- 没有解决我的问题, 去提问

