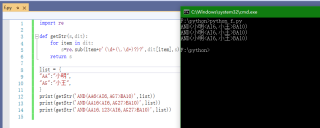
text='AND(AA6<AI6,AG7>BA10)' # 原文
# 替换字典
list = {
"AA":"小明",
"AG":"小王",
}
# 希望达到如下效果
text_new='AND(小明<AI6,小王>BA10)'
# 仅完全匹配,是无法把小明,小王后面的数字替换的
for item in list:
text_new = score_formula.replace(item,list[item])
#text_new='AND(小明6<AI6,小王7>BA10)'
# 我试着写正则,但是失败了
for item in list:
reg=re.compile(list[item] +"d+")
match=reg.search(text)
该怎么优化呢??