目标检测ssd和fast rcnn等算法可以识别并定位物体,可是应该如何在框出目标物体时,能显示物体中心或者边框的xy常规坐标,实现了一些代码,但存在问题,求大神帮忙
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# 获得图中所有op
ops = tf.get_default_graph().get_operations()
# 获得输出op的名字
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
# 如果tensor_name在all_tensor_names中
if tensor_name in all_tensor_names:
# 则获取到该tensor
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[1], image.shape[2])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
# 图片输入的tensor
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# 传入图片运行模型获得结果
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: image})
# 所有的结果都是float32类型的,有些数据需要做数据格式转换
# 检测到目标的数量
output_dict['num_detections'] = int(output_dict['num_detections'][0])
# 目标的类型
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
# 预测框坐标
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
# 预测框置信度
output_dict['detection_scores'] = output_dict['detection_scores'][0]
boxes = np.squeeze(output_dict['detection_boxes'])
scores = np.squeeze(output_dict['detection_scores'])
#set a min thresh score, say 0.8
min_score_thresh = 0.8
bboxes = boxes[scores > min_score_thresh]
#get image size
im_width, im_height = image.size
final_box = []
for box in range(bboxes):
ymin, xmin, ymax, xmax = box
final_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])
return output_dict
#for root,dirs,files in os.walk('test_images/'):
for root,dirs,files in os.walk('test/'):
for image_path in files:
# 读取图片
image = Image.open(os.path.join(root,image_path))
# 把图片数据变成3维的数据,定义数据类型为uint8
image_np = load_image_into_numpy_array(image)
# 增加一个维度,数据变成: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# 目标检测
output_dict = run_inference_for_single_image(image_np_expanded, detection_graph)
# 给原图加上预测框,置信度和类别信息
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
use_normalized_coordinates=True,
line_thickness=8)
# 画图
# print ("box : ", final_box)
plt.figure(figsize=(12,8))
plt.imshow(image_np)
plt.axis('off')
plt.show()
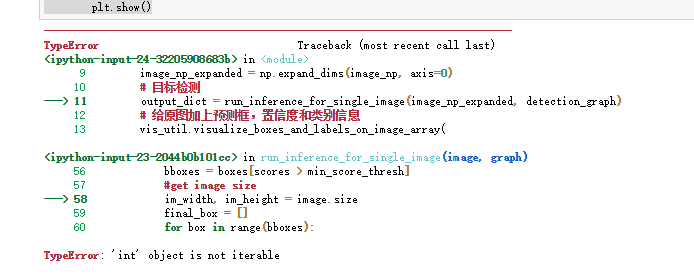
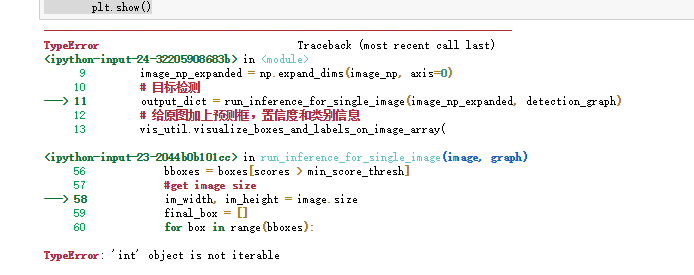
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-24-32205908683b> in <module>
9 image_np_expanded = np.expand_dims(image_np, axis=0)
10 # 目标检测
---> 11 output_dict = run_inference_for_single_image(image_np_expanded, detection_graph)
12 # 给原图加上预测框,置信度和类别信息
13 vis_util.visualize_boxes_and_labels_on_image_array(
<ipython-input-23-2044b0b101cc> in run_inference_for_single_image(image, graph)
56 bboxes = boxes[scores > min_score_thresh]
57 #get image size
---> 58 im_width, im_height = image.size
59 final_box = []
60 for box in range(bboxes):
TypeError: 'int' object is not iterable
```