

问题描述:
想要爬取标题以及图片,但是图片却怎么都爬不出来也不报错,不知道问题在哪里
代码如下
运行结果如图所示
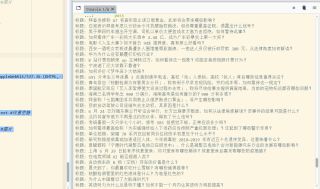
import requests
from bs4 import BeautifulSoup
import re
import os
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"}
url="https://www.zhihu.com/billboard"
html=requests.get(url,headers=headers)
soup=BeautifulSoup(html.text,'lxml')
divs=soup.select('.HotList-item')
num=0
for div in divs:
title=div.select(' .HotList-itemBody .HotList-itemTitle')[0].text
print('标题:',title)
try:
img=div.select(' .HotList-itemimgContainer img')[0]['src']
print(img)
if not os.path.exists('zhihu'):
os.mkdir('zhihu')
with open('zhihu/{}.jpg'.format(num),'wb') as f:
f.write(requests.get(img).content)
num+=1
except:
pass






