
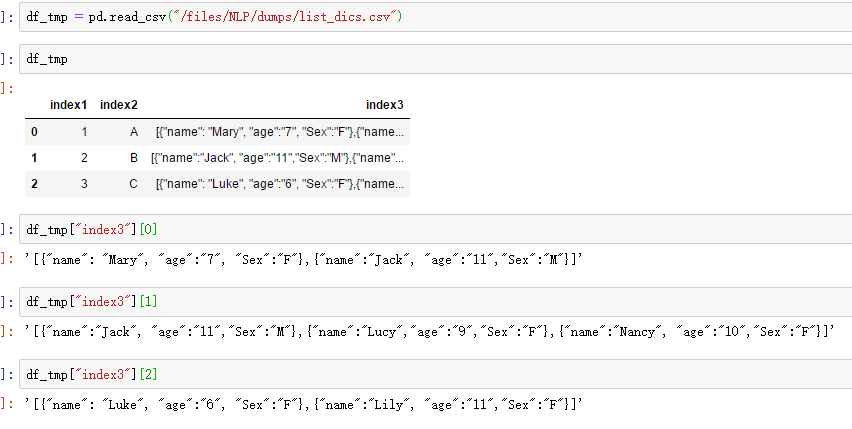
说明:原始数据导进来,index3是字符串格式(json)。
需求:提取index3里字典格式下所有“name”的值。
现有思路:用json.loads转码成list of dictionaries格式,然后循环遍历index3,遍历list所有字典,遍历字典里的key值,判断字典key=="name",取value。
说明:同一个list里面多个dictionary,且key值有重复;json转码前带单引号字符串str。
问题:三层循环,数据量稍微大一点速度极慢,求大神帮帮忙有没有新的思路!






