

第一次接触python爬虫,最近做项目需要爬取一些游戏数据。
如图所示,我要爬取这些英雄的图片和数字,
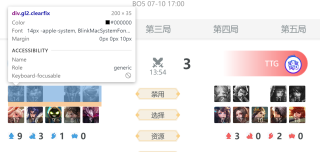
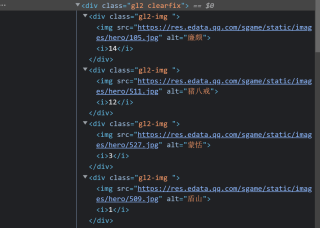
该网页对应的html代码是这样的,
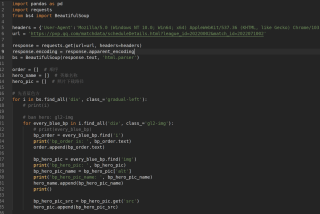
我的代码如下,
但是出来的结果是这样的,
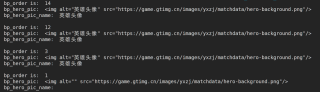
就比如bp_hero_pic这里,正确的输出结果应该是这样的,
<img src="https://res.edata.qq.com/sgame/static/images/hero/105.jpg" alt="廉颇">
但是却变成了
<img alt="英雄头像" src="https://game.gtimg.cn/images/yxzj/matchdata/hero-background.png"/>
是因为图片设置了反爬吗?应该怎么解决呢?求指点指点~







