问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
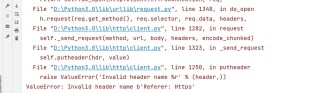
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
import urllib.request
url = 'https://weibo.cn/6543875713/info'
headers = {
# ':authority':' weibo.cn',
# ':method':' GET',
# ':path':' /6543875713/info',
# ':scheme':' https',
'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
#'accept-encoding':' gzip, deflate, br',
'accept-language':' zh-CN,zh;q=0.9',
'cache-control':' max-age=0',
'cookie':' _T_WM=97537cddb6b9372bb7cc7f52fdc76b9b; SCF=AqL1oCWI4guZx3smWyY8gt4RjJJway9lF75jEzSQn3n7WW_HwaQF1LEQWnI-vFIkbE_wfJJfC4fF0_s4IWrNvIw.; SUB=_2A25P0G-DDeRhGeBL71EZ9yvLyj-IHXVtO3HLrDV6PUJbkdCOLWmskW1NRxsmyRw2gXUTJs0XRzgTW-sQkWRgwqGV; SSOLoginState=1658068947',
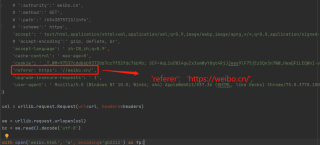
'referer: https':'//weibo.cn/',
'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
usl = urllib.request.Request(url=url,headers=headers)
we = urllib.request.urlopen(usl)
bc = we.read().decode('utf-8')
with open('weibo.html','w',encoding='gb2312')as fp:
fp.write(bc)