有一个3十万条的字典表,导入sqlite,并且对前两个字段创建索引。步骤1
模拟创建了一个3百万条的记录,步骤2,想把这个表与步骤1中的字典表进行匹配,查询country的值
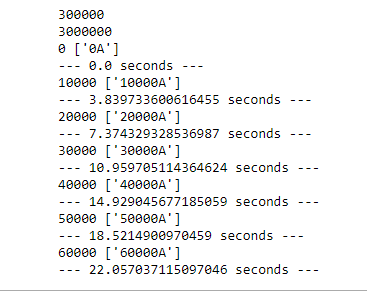
步骤3, 对步骤2中的3百万条记录的表进行遍历,每执行1万条记录,打印所需时间,为啥这个时间间隔越来越大?
import sqlite3
import time
connection=sqlite3.connect("aquaium.db")
cursor=connection.cursor()
cursor.execute("DROP table IF EXISTS ip_addr")
cursor.execute("create table ip_addr (start_ip integer,end_ip integer, country Text)")
# 1 创建的一个字典表,包含3十万条如下记录
'''
0,4,‘0A’
5,9,'5A'
......
'''
tmp=[]
i=0
ip_lst=[]
while(i<300000):
ip_lst.append([i*5,i*5+4,str(i*5)+'A'])
i+=1
print(len(ip_lst))
for a in ip_lst:
tmp=[a[0],a[1],a[2]]
cursor.execute("insert into ip_addr (start_ip,end_ip,country) values(?,?,?)",tmp)
connection.commit()
cursor.execute("create index index_ip on ip_addr(start_ip,end_ip)")
#2 创建一个3百万的list,其中的每个元素为一个列表。
'''
[0,'']
[1,'']
......
[3000000,'']
'''
myip=[]
i=0
while(i<3000000):
myip.append([i,''])
i+=1
print(len(myip))
#3 对上述3百万的列表进行遍历,依次从1中创建的字典表中检出‘country’的值, 每执行1万条查询,打印出所用
# 时间,为啥下面的这段循环进行起来越来越慢????
i=0
start_time = time.time()
while(i<len(myip)):
cursor.execute("select country from ip_addr where (%d >=start_ip and %d<=end_ip)" %((i%300000),(i%300000)))
test1=list(cursor.fetchone())
if i%10000==0:
print(i,test1)
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
i+=1
cursor.close()
connection.close()
下面是输出,为啥每次执行1万条查询的时间越来越大?3->7->10->14->18->22?
面