问题遇到的现象和发生背景
爬取一个网站的表单,从表单中提取文本
url = "http://tjj.hunan.gov.cn/hntj/tjfx/tjgb/rkpc/202105/t20210519_19079329.html"
问题相关代码,请勿粘贴截图

我的解答思路和尝试过的方法
我想要达到的结果

爬取一个网站的表单,从表单中提取文本
url = "http://tjj.hunan.gov.cn/hntj/tjfx/tjgb/rkpc/202105/t20210519_19079329.html"
 分享
分享
 关注
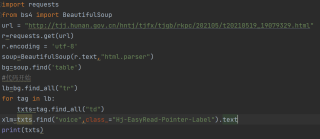
关注from bs4 import BeautifulSoup as bs
from requests import get
import re
Agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
url = 'http://tjj.hunan.gov.cn/hntj/tjfx/tjgb/rkpc/202105/t20210519_19079329.html'
data = get(url,headers = {'User-Agent':Agent})
data.encoding='utf-8'
soup = bs(data.text,'html.parser')
table = soup.find('table')
message = table.find_all("td")
t = []
with open('test20220728.txt','w', encoding='utf-8') as fn:
for i,n in enumerate(message[11:]):
t.append(re.findall(r'>(.+?)<', str(n))[0].strip())
if i%5==4:
x = '<span style="font-size:10.0pt;font-family:宋体">'
x = ','.join(t).replace(x,'')
print(x, file = fn)
t = []
print('处理完成!\n')
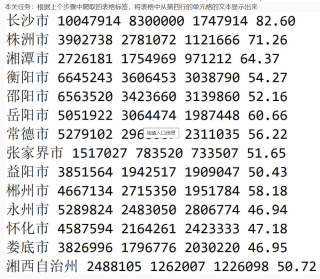
长沙市,10047914,8300000,1747914,82.60
株洲市,3902738,2781072,1121666,71.26
湘潭市,2726181,1754969,971212,64.37
衡阳市,6645243,3606453,3038790,54.27
邵阳市,6563520,3423660,3139860,52.16
岳阳市,5051922,3064474,1987448,60.66
常德市,5279102,2968067,2311035,56.22
张家界市,1517027,783520,733507,51.65
益阳市,3851564,1942517,1909047,50.43
郴州市,4667134,2715350,1951784,58.18
永州市,5289824,2483050,2806774,46.94
怀化市,4587594,2164261,2423333,47.18
娄底市,3826996,1796776,2030220,46.95
湘西自治州,2488105,1262007,1226098,50.72
分享 系统已结题
8月6日
系统已结题
8月6日 已采纳回答
7月29日
创建了问题
7月28日
已采纳回答
7月29日
创建了问题
7月28日


