
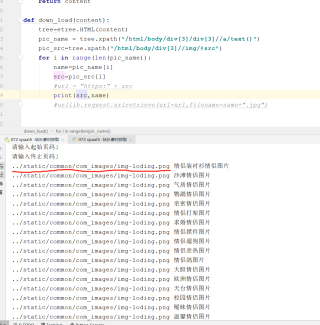
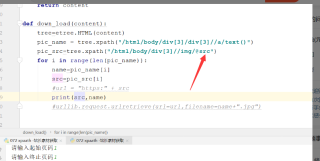
为什么同样的xpath路径 在xpath中和pycharm中显示的内容不一样,pycharm中的这个路径也确实获取不了网页中的内容。
这是网页源码
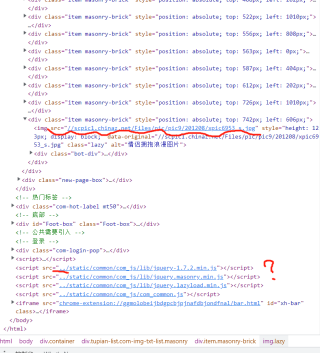
这是全部代码




这是网页源码
这是全部代码
 分享
分享
第二张图明显题主是开发工具审核dom进行查看,这个并不是源代码,审核dom得到的html代码有可能被js修改过,而request之类得到的是源代码
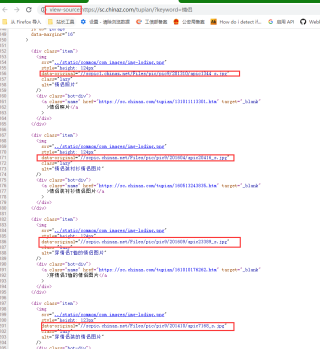
下面这种才叫源代码,src是默认的加载等待图片,实际图片网址存储在data-original属性中,然后通过js来动态加载图片
分享 系统已结题
9月10日
系统已结题
9月10日 已采纳回答
9月2日
修改了问题
8月9日
创建了问题
8月9日
已采纳回答
9月2日
修改了问题
8月9日
创建了问题
8月9日

