

问题遇到的现象和发生背景
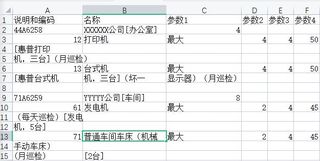
前面两个,打印机和台式机是绝大部分的格式,后面两个发电机和车床格式比较乱,用列表处理,并且把编码改成了纯数字
问题相关代码,请勿粘贴截图
这是要处理的文本
说明和编码,名称,参数1,参数2,参数3,参数4
446258,X公司[办公室],4,,,
12,打印机,最大,4,4,50
[惠普打印,,,,,
机,三台](月巡检),,,,,
13,台式机,最大,4,4,50
[惠普台式机,机,三台](坏一,显示器)(月巡检),,,
,,,,,
716259,Y公司[车间],8,,,
61,发电机,最大,2,4,45
(每天巡检)[发电,,,,,
机,5台],,,,,
71,普通车间车床(机械,最大,2,4,45
手动车床),,,,,
(月巡检),[2台],,,,
下面使用列表处理,结果前几个都对,后面的有重复,不知哪儿错了
导入到excel里读取,空白项会自动填充nan
pc=pd.read_excel(open('test.xlsx', 'rb'), sheet_name='test')
plist=pc.values.tolist()
print('长度是:',len(plist))
aa=[]
bb=[]
for i in range(len(plist)):
try:
type(int(plist[i][0]))==int
aa.append(plist[i])
except:
ii=len(aa)-1
aa[ii][1]=str(aa[ii][1])+str(plist[i][0])
if str(plist[i][1]) != 'nan':
aa[ii][1] = str(aa[ii][1]) + str(plist[i][1])
if str(plist[i][2]) != 'nan':
aa[ii][1] = str(aa[ii][1]) + str(plist[i][2])
if str(plist[i][3]) != 'nan':
aa[ii][1] = str(aa[ii][1]) + str(plist[i][3])
if str(plist[i][4]) != 'nan':
aa[ii][1] = str(aa[ii][1]) + str(plist[i][4])
print(aa)
打印结果,第三个开始重复
[[446258, 'XXXXXX公司[办公室]', 4, nan, nan, nan],
[12, 'nan[惠普打印机,三台](月巡检)', '最大', 4.0, 4.0, 50.0],
[13, '台式机13台式机13最大4.04.0[惠普台式机显示器](月巡检)nan', '最大', 4.0, 4.0, 50.0],
[716259, 'YYYYY公司[车间]716259YYYYY公司[车间]7162598', 8, nan, nan, nan],
[61, '发电机61发电机61最大2.04.0(每天巡检)[发电机,5台]', '最大', 2.0, 4.0, 45.0],
[71, '普通车间车床(机械71普通车间车床(机械71最大2.04.0手动车床)(月巡检)[2台]', '最大', 2.0, 4.0, 45.0]]
我想要达到的结果









