我最近想要学习python,想从爬虫开始,应为本人还在上学,只学过java与c#桌面编程,所以有一定基础,但学的不深。在今天我所编写的爬虫中,我的爬虫爬取到了我所想要的网页内容,结果在输出成txt文档时,老是输出成空的文档,我在csnd里搜索“python输出txt文档”找了几个输出txt文档的代码,结果在代码运行完后,控制台输出了我想要的结果,但我的txt文档是空的,不知道是哪里错了。
以下是我编写的代码
from urllib import request
url = 'https://fanqienovel.com/reader/6924594094115127816' # 要爬取内容的网址
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 '
'Safari/537.36 ' # 要爬取网站的 user-agent
}
req = request.Request(url=url, headers=headers)
rsp = request.urlopen(req)
print(rsp.read().decode('utf-8')) # 以utf-8编码输出到控制台
file_handle = open('G:/txt.txt', mode='a') # 打开要读取的txt文档
file_handle.write(rsp.read().decode('utf-8')) # 将爬取的内容写入txt.txt文件
file_handle.close() # 关闭txt.txt文档
代码截图:
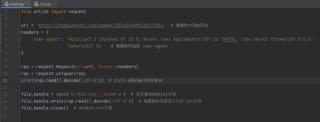
控制台是没问题的
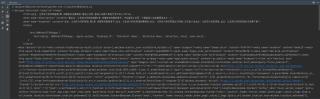
但txt文档是空的
我在代码里经过多次尝试却始终无法发现所在的问题,以下是我所做的尝试:
import fileinput
from urllib import request
url = 'https://fanqienovel com/reader/6924594094115127816' # 要爬取内容的网址
headers = {
'user-agent': 'Mozilla/5 0 (Windows NT 10 0; Win64; x64) AppleWebKit/537 36 (KHTML, like Gecko) Chrome/104 0 0 0 '
'Safari/537 36 ' # 要爬取网站的 user-agent
}
req = request Request(url=url, headers=headers)
rsp = request urlopen(req)
print(rsp read() decode('utf-8')) # 以utf-8编码输出到控制台
path2 = r'G:\txt txt'
file2 = open(path2, 'w+')
file2 write(rsp read() decode('utf-8'))
fileinput close()
import fileinput
from urllib import request
url = 'https://fanqienovel.com/reader/6924594094115127816' # 要爬取内容的网址
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 '
'Safari/537.36 ' # 要爬取网站的 user-agent
}
req = request.Request(url=url, headers=headers)
rsp = request.urlopen(req)
print(rsp.read().decode('utf-8')) # 以utf-8编码输出到控制台
with open("G:/txt.txt", "w") as f:
f.write(rsp.read().decode('utf-8'))
这两个代码都是输出txt文档时,文档输出是空的,我觉得应该是“rsp read() decode('utf-8')”这串代码需要转换成其他代码,但是我不知道怎么转换,也不知道怎么搜索。
我想要的结果很简单,就是将控制台输出的内容输出成txt文档。
(如下图)(下图是复制粘贴,不是输出)

请问我的代码出了什么问题和怎么样解决?