

问题遇到的现象和发生背景
Python给Dataframe循环添加列时数据会被吞
我在用Python给一个表格循环添加列时,循环次数超过75次,得出的结果会少一列数据。循环次数少于75时,前74列数据都能正常得出,但当循环次数到75次时,前74列数据正常,无第75列数据;然而当我把循环次数改为76次时,前74列数据正常,第75列数据反而是本该在第76列的数据,本应该有76列数据的,只出现了75列数据;当我把循环次数改为86次时,结果只有85列,少的那一列还是本该在第75列的数据
问题相关代码,请勿粘贴截图
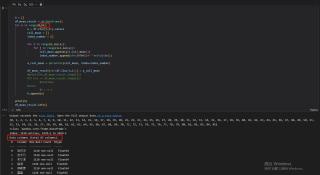
N = []
df_mean_result = pd.DataFrame()
for n in range(0,76):
a = df.iloc[n,6:].values
cell_mean = []
index_number = []
for i in range(0,len(a)):
for j in range(i+1,len(a)):
cell_mean.append(a[i:j+1].mean())
index_number.append(str(1970+i)+'—'+str(j-i+1))
a_cell_mean = pd.Series(cell_mean, index=index_number)
df_mean_result[str(df.iloc[n,1])] = a_cell_mean
N.append(n)
print(N)
df_mean_result.info()
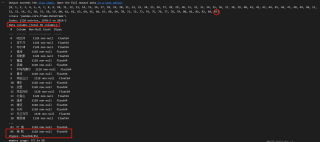
运行结果及报错内容
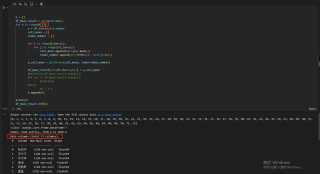
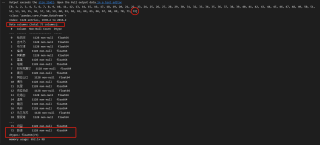
当循环次数是73次时
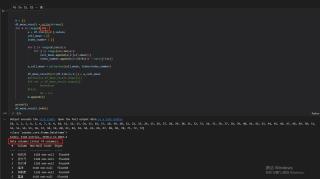
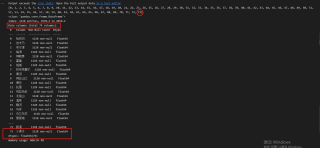
当循环次数是74次时
当循环次数是75次时
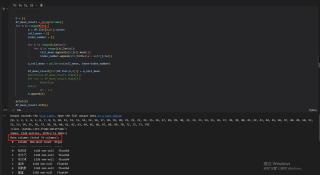
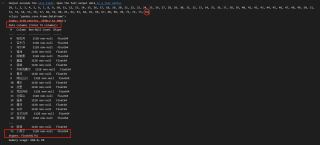
当循环次数是76次时
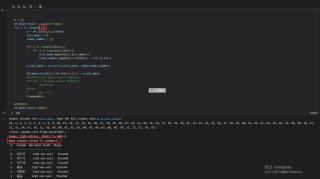
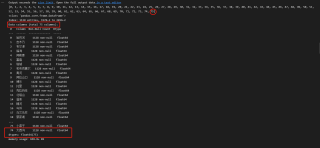
当循环次数是86次时
我的解答思路和尝试过的方法
代码中的N 我是用来记录n有没有缺漏,结果表明,循环都做了,但是在追加列的时候,就是少了本应该在第75列的数据。循环74次和循环75次得到的结果一样,第76次到86次时,总会少一列。按照原始的表格顺序,第75列应该是“巴伦台”,第76列应该是“大西沟”
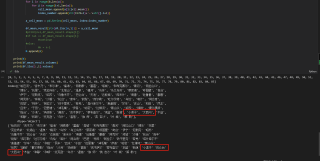
我想要达到的结果
想问问各位,能否给个合情合理的解释,由于研究原因,计算数据不方便共享,程序的其他部分均没问题,就是想问问各位在python中做Dataframe是否有过类似的问题,是不是会吞数据?这种情况是Dataframe的数据存储结构缺陷造成的原因么?







