问题遇到的现象和发生背景
背景:本人想用python是想解决下办公自动化的问题。现在有一组时间序列数据,比如下图
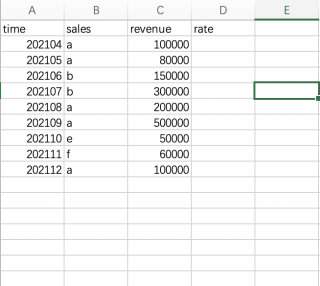
现在是每人当月的revenue决定下个月的rate,100000以内,下个月的提成点是6%,rate=6%;如果100000到200000,那么下个月的提成点是10%,rate=10%;如果本月达到200000以上,那么下个月的提成点是14%。注意是下个月点数。本月的收入决定下个月的提成点数。现在想要用python pandas 编一个函数解决这个问题

背景:本人想用python是想解决下办公自动化的问题。现在有一组时间序列数据,比如下图
 分享
分享 # coding=utf-8
import pandas as pd
from datetime import date
date = date.fromisoformat
join = '-'.join
def date2int(d: int) -> int:
"""将数字转换为日期格式,减去一个月,返回6位(YYYYMM)十进制整数。"""
d = str(d)
d = d[:4], d[4:], '01'
d = date(join(d)) # 检验日期数据
m = d.month - 1
d = f'{d.year}{m:02}' if m else f'{d.year - 1}12' # 检验月份
return int(d)
def rate(rv: float) -> float:
"""依据业绩返回提成比例,默认提成比例返回None"""
if rv >= 200000:
return 0.14
if rv >= 100000:
return 0.10
def get_rate(tsr, row) -> float:
"""依据上个月业绩取提成比例,没有业绩返回默认提成比例"""
if sr := tsr.get(date2int(row.time)):
if rt := sr.get(row.sales):
return rt
return 0.06 # 100000以下的默认提成比例
def set_rate(data) -> dict:
"""生成{time:{sales:rate}}数据结构,以优化提成比例的查找性能"""
tsr = {}
for row in data.itertuples():
t = row.time
sr = {row.sales: rate(row.revenue)}
if tsr.setdefault(t, sr) is not sr:
tsr[t].update(sr)
return tsr
def award(data):
dt = data.T # 数据转置,行轴
tsr = set_rate(data)
for row in data.itertuples():
_rate = get_rate(tsr, row)
dt[row.Index]['rate', 'award'] = _rate, _rate * row.revenue
return dt.T
if __name__ == '__main__':
revenue = pd.read_excel(r'C:\pyt.xlsx')
sales_award = award(revenue)
print(sales_award)
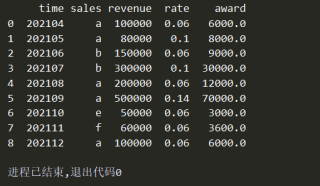
分享 系统已结题
8月30日
系统已结题
8月30日 已采纳回答
8月22日
创建了问题
8月20日
已采纳回答
8月22日
创建了问题
8月20日

