

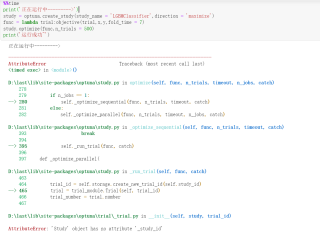
这里代码运行不知道为啥出现了错误,检查了很久也没有找到原因,请大家帮我看一看~
# 参数:trial,特征,标签,需要优化的超参数,交叉验证次数
def objective(trial, x, y,fold_time):
# 参数填充区域(此处根据需要修改)
# 需要调优的参数
params_grid = {'n_estimators':trial.suggest_int('n_estimators',50,1500),
'learning_rate':trial.suggest_float('learning_rate',0.01,0.3), # 学习率
'num_leaves':trial.suggest_int('num_leaves',10,100), # 一棵树的最大叶子数
'max_depth':trial.suggest_int('max_depth',3,100), # 树模型的最大深度
'min_data_in_leaf':trial.suggest_int('min_data_in_leaf',5,100), # 一个叶子中的最小数据数
'max_bin':trial.suggest_int('max_bin',10,300), # 存储特征值的最大 bin 数
"lambda_l1": trial.suggest_int("lambda_l1", 0, 100, step=5), # L1 正则化
"lambda_l2": trial.suggest_int("lambda_l2", 0, 100, step=5), # L2 正则化
"min_gain_to_split": trial.suggest_float("min_gain_to_split", 0, 15), # 执行拆分的最小增益
"bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 1.0, step=0.1), # 随机选择部分数据而不重新采样
"bagging_freq": trial.suggest_int("bagging_freq",1,20), # 每k次迭代执行bagging
"feature_fraction": trial.suggest_float("feature_fraction", 0.2, 1.0, step=0.1) # 选择特征比例
}
# 交叉验证设置(回归用KFold,分类用StratifiedKFlod)
cv = StratifiedKFold(n_splits=fold_time, shuffle=True, random_state=2022)
# 此处通过创建空数组用于记录预测分数
# cv_scores = np.empty(fold_time)
cv_scores = np.zeros(fold_time)
# 训练集和测试集的划分
for idx, (train_idx, test_idx) in enumerate(cv.split(x, y)):
X_train, X_test = x.iloc[train_idx], x.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
# lightGBM的分类器/回归器初始化(此处根据需要修改)
model = lgbm.LGBMClassifier(boosting = 'gbdt',
objective='binary',
n_jobs = -1,
force_row_wise = True,
**params_grid)
# 填充训练数据进行测试
model.fit(
X_train,
y_train,
eval_set=[(X_test, y_test)],
eval_metric='auc',
early_stopping_rounds=50,
callbacks = [LightGBMPruningCallback(trial,'auc')],# 对数据进行训练之前检测出不太好的超参数集,从而显着减少搜索时间。
verbose = False # 不显示训练过程
)
# 获得模型的预测分数
pred_score = model.score(X_test,y_test)
# 将预测分数填入空数组中
cv_scores[idx] = pred_score
# 返回预测平均值
return np.mean(cv_scores)
%%time
print('正在运行中--------->')
study = optuna.create_study(study_name = 'LGBMClassifier',direction = 'maximize')
func = lambda trial:objective(trial,x,y,fold_time = 7)
study.optimize(func,n_trials = 500)
print('运行成功~')






