
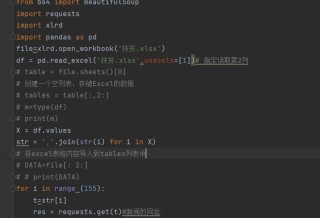
最后一个语句,想使用for循环实现爬虫对个网址,我把Excel表格内已有的网址那一列单独转化为了字符串格式想通过for循环依次传入request.get()失败了,有什么解决办法吗,或者有什么其他可以爬虫对个网址的代码吗,求解

 分享
分享
 关注
关注str返回的是1列表吗?把str打印出来看看
分享 系统已结题
9月23日
系统已结题
9月23日 已采纳回答
9月15日
创建了问题
9月1日
已采纳回答
9月15日
创建了问题
9月1日
