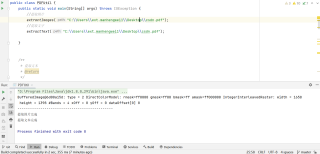
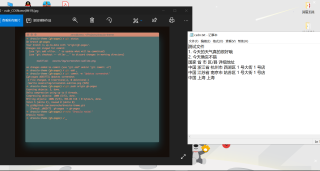
java 提取pdf/word文件内容,需要保持原文排版提取
下面的测试文件地址
https://hzaihe-1304269943.cos.ap-shanghai.myqcloud.com/markdown/csdn.docx
https://hzaihe-1304269943.cos.ap-shanghai.myqcloud.com/markdown/csdn.pdf
难点说明:在读取文件的时候无法做到一行一行的读取 并且在读取的时候能够判断出来当前的元素属性是否是表格 文字 图片 等,只能单一的提取 由于表格中的内容也是文字 在文字提取的时候就会把表格的文字提取出来,而使用表格提取的话可以精表格中的内容出来但文字就会丢失,下面是我通过两种方式提取的内容,表格做了分割处理
我的解答思路和尝试过的方法,我尝试过多种方法来解决这个问题 希望能够循环读取每一页文件的每一行元素,但尝试了好多都没有这些方法,也想过将文件转换成XML来解决通过标签来解决,但最后失败了
提取纯文字(这不是我想要的,应为把表格也提取出来了,只希望到2. 今天确实不错 结束)
测试文件
1. 今天的天气真的很好哦
2. 今天确实不错
国家 省 市 区/县 详细地址
中国 浙江省 杭州市 西湖区 1 号大街 1 号店
中国 江苏省 南京市 姑苏区 1 号大街 1 号店
中国 上海 上海
提取表格
[
{
"textList":[
{
"rowId":"1_1",
"text":"国家"
},
{
"rowId":"1_2",
"text":"省"
},
{
"rowId":"1_3",
"text":"市"
},
{
"rowId":"1_4",
"text":"区/县"
},
{
"rowId":"1_5",
"text":"详细地址"
},
{
"rowId":"2_1",
"text":"中国"
},
{
"rowId":"2_2",
"text":"浙江省"
},
{
"rowId":"2_3",
"text":"杭州市"
},
{
"rowId":"2_4",
"text":"西湖区"
},
{
"rowId":"2_5",
"text":"1号大街1号店"
},
{
"rowId":"3_1",
"text":"中国"
},
{
"rowId":"3_2",
"text":"江苏省"
},
{
"rowId":"3_3",
"text":"南京市"
},
{
"rowId":"3_4",
"text":"姑苏区"
},
{
"rowId":"3_5",
"text":"1号大街1号店"
},
{
"rowId":"4_1",
"text":"中国"
},
{
"rowId":"4_2",
"text":"上海"
},
{
"rowId":"4_3",
"text":"上海"
}
],
"type":"table",
"id":1
}
]