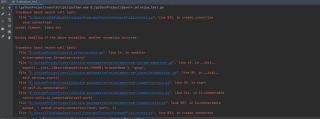
问题遇到的现象和发生背景
最近刚开始学习python爬虫,跟着教程学习selenium后目前遇到以下报错,在多次尝试网上其他解决方案后仍然无法解决,还请各位帮忙看看错误原因,万分感谢。
问题相关代码,请勿粘贴截图
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(executable_path="C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe")
driver=webdriver.Chrome(service=s)
driver.maximize_window()
driver.get('https://www.baidu.com')
driver.quit()
运行结果及报错内容