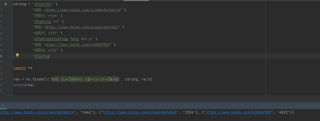
python 正则表达式匹配网址
原文如下:
dfgdfshh
链接:https://www.baidu.com/s/aabcdefghijk
提取码:r6az
dfgdfsgg fd
链接:https://www.baidu.com/s/aabcdef4563
提取码:1234
dfgdfsgg
dfgdfsgg fdsg dfs g
链接:https://www.baidu.com/s/8869988
提取码:4321
dfgdfsg
……
我想正则匹配原文中这类内容
https://www.baidu.com/s/aabcdefghijk
提取码:r6az
https://www.baidu.com/s/aabcdef4563
提取码:1234
https://www.baidu.com/s/8869988
提取码:4321
我的正则表达式
urls = re.findall('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!(),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+[\n]提取码.',line)
一直不成功!