
处理bed文件,把第四列内容拆分提取出来
存放在字典里,
并输出为txt或者json文件
字典名为patient_genename
例子:ENSG00000186092:OR4F5处理为patient_genename['ENSG00000186092']='OR4F5'
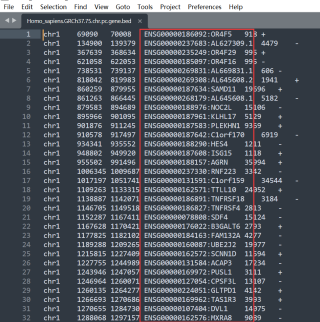

处理bed文件,把第四列内容拆分提取出来
存放在字典里,
并输出为txt或者json文件
字典名为patient_genename
例子:ENSG00000186092:OR4F5处理为patient_genename['ENSG00000186092']='OR4F5'
 分享
分享
各个列是用制表符分隔的吗?试试下面的可不可以:
import pandas as pd
patient_genename = {}
df = pd.read_csv('file.bed', sep='\t', header=None)
for item in df[3]:
kv = item.split(':')
patient_genename[kv[0]] = kv[1]
 系统已结题
9月27日
系统已结题
9月27日 已采纳回答
9月19日
创建了问题
9月18日
已采纳回答
9月19日
创建了问题
9月18日


