
我想用pandas计算列表中id的出现次数,并输出超过50次的行数据,存进一张新表怎么写啊
for index,row in df1.iterrows():
for i in row:
if row["id"].value_counts()>50:
print(row)
这怎么写都报错呢

我想用pandas计算列表中id的出现次数,并输出超过50次的行数据,存进一张新表怎么写啊
for index,row in df1.iterrows():
for i in row:
if row["id"].value_counts()>50:
print(row)
这怎么写都报错呢
 分享
分享
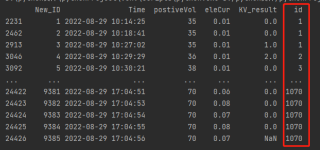
newDf = pd.DataFrame(columns=['New_ID', 'Time', 'positiveVol', 'eleCur', 'KV_result', 'id'])
for key, item in df1.groupby(['id']):
if item.shape[0] > 50:
item['id'] = key[0]
newDf = pd.concat([newDf , item])
print(item)
# 最后把这个newDf 存进新表就好了
 系统已结题
10月1日
系统已结题
10月1日 已采纳回答
9月23日
创建了问题
9月23日
已采纳回答
9月23日
创建了问题
9月23日

