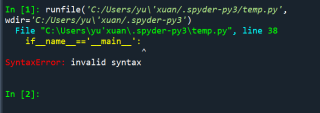
爬虫过程中遇到了这个错误,该怎么解决?
from selenium import webdriver
import csv
import time
def csv_writer(item):
with open('weibo.csv','a',encoding='gbk',newline='')as csvfile:
writer=csv.writer(csvfile)
try:
writer.writerow(item)
except:
print('写入失败')
def login():
driver.get('https://weibo.com/')
time.sleep(5)
driver.set_window_size(1920,1080)
username=driver.find_element_by_xpath('//*[@id="loginname"]')
username.send_keys('your username')
password=driver.find_element_by_name('password')
password.send_keys('your password')
submit=driver.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[3]/div[6]/a')
print('准备登陆....')
submit.click()
time.sleep(4)
def spider():
driver.get('https://weibo.com/')
time.sleep(4)
all_weibo=driver.find_element_by_xpath('//*[@id="scroller"]/div[1]/div[1]/div/article/div')
for weibo in all_weibo:
pub_id=weibo.find_element_by_xpath('header/div[1]/div/div[1]/a/span')[0].text
pun_id_url=weibo.find_element_by_xpath('header/div[1]/div/div[1]/a/span')[0].get_attribute('href')
pub_content=weibo.find_element_by_xpath('div/div[1]/div')[0].text
item=[pub_id,pun_id_url,pub_content]
print('成功抓取',pub_id)
csv_writer(item)
if__name__=='__main__':
driver=webdriver.Chrome(r'd:/seleenium/chromedriver.exe')
login()
while True:
spider()
time.sleep(300)