s1复用了s的字面量,为什么它俩地址还是不一样的呀?怎么判断引用变量的地址是否一样?


s1复用了s的字面量,为什么它俩地址还是不一样的呀?怎么判断引用变量的地址是否一样?
 分享
分享
 关注
关注
其实要搞懂这个问题,你必须要对JVM的内存模型和类的加载顺序有一定了解,没关系,由我在这里给你提炼概括,相信能让你更加理解,当然更建议系统学习一下我刚才说的这两个东西
那么好,我先来给你解释为什么 String s=new String("hello"); 创建了两个对象,这里我先直接告诉你 —— 这里创建的两个对象分别是 String 和 "hello" 。
然后要理解原理,首先你要理解的一点是 —— 通常情况下,【对象】二字我们都是相对于【堆】来说的,而【堆】中又包含了【常量池】。
你先好好理解我纯手敲出的这段话,然后再结合后面的图理解:
那么这里的两个对象肯定就是指的在【堆】里创建了两个对象了,而堆里又包含了【常量池】,这个【常量池】 里就包含了一个叫【字符串常量池】的东西,而这些东西都是在加载 class 文件时放进去的,这个时候创建了 对象 "hello" 放进了【字符串常量池】里。
上面class文件加载时的用图描述就是这样的:
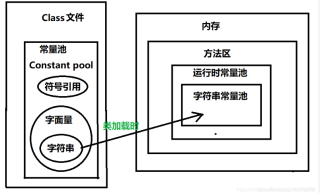
好了,上面说完了class文件的加载过程,那么在所有class文件加载完后。不是要开始正式跑程序了?也就是在这个运行程序的过程中创建了对象 String。
那么好了,我上这句话里解释了原因,由于在运行时又创建了一个String,所以你 String s=new String("hello"); 的这个 s 指向的地址其实就是这个运行时创建的 String 了。 而 String s1="hello"; 由于没有 new 一个新的String对象,所以直接指向的就是常量池中的 "hello" 字符串 —— 因为这指向的是两个完全不同的对象,所以地址自然不同,理解了吗 ?
每一个字,全程手敲,如有帮助,还望采纳,如果不理解请继续问我,谢谢!
补充: 上图的方法区在jdk1.7移除了,但是常量还是包裹在堆里的,结果没变,不影响你理解。当然我还是那句话,就算我的提炼解释对你有一定帮助,还是建议你去学习一下 【JVM的内存模型】 和 【类的加载顺序以及过程】,这样会让你理解的更加透彻 !
分享  系统已结题
10月3日
系统已结题
10月3日 已采纳回答
9月25日
已采纳回答
9月25日 专家修改了标签
9月25日
创建了问题
9月25日
专家修改了标签
9月25日
创建了问题
9月25日


