使用sklearn库diabetes数据集
请问怎么改可以提升学得模型性能(调整测试集、训练集比例,选择不同特征组合,调整线性函数参数),R2不小于0.47
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
diabetes=datasets.load_diabetes()
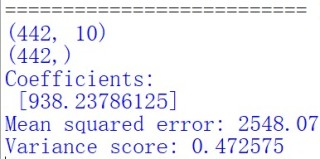
print(diabetes.data.shape)
print(diabetes.target.shape)
diabetes_X=diabetes.data[:,np.newaxis,2]
diabetes_X_train=diabetes_X[:-20]
diabetes_X_test=diabetes_X[-20:]
diabetes_y_train=diabetes.target[:-20]
diabetes_y_test=diabetes.target[-20:]
regr=linear_model.LinearRegression() #实例化线性回归
regr.fit(diabetes_X_train,diabetes_y_train) #拟合
diabetes_y_pred=regr.predict(diabetes_X_test) #预测
print('Coefficients: \n', regr.coef_) #系数
print ("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test,diabetes_y_pred)) #均方误差
print('Variance score: %2f' % r2_score(diabetes_y_test,diabetes_y_pred)) #R2
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.title('LinearRegression Diabetes')
plt.xlabel('Attributes')
plt.ylabel('Measure of disease')
plt.show()