
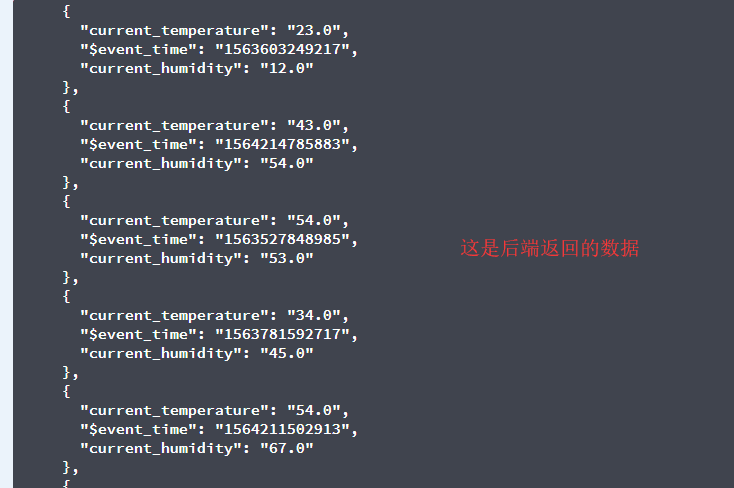
前端:
let i=res.data.length;//长度
let j;
let date=[];//接收时间戳$sevent_time
var d=[];//用于接收初始化后的时间戳
var dd=[];//用于接收转化为年月日格式的数组集
for(j=0;j<i;j++){
date[j]=res.data[j].$event_time;//遍历时间戳
consul.log(date[j]);//打印出来是时间戳的格式
d[j]=new Date(date[j]);//初始化时间戳
consul.log(d);//打印出来的内容为Invalid Date。
dd=d[j].getFullYear() + '-' + (d[j].getMonth() + 1) + '-' + d[j].getDate() + ' ' + d[j].getHours() + ':' + d[j].getMinutes() + ':' + d[j].getSeconds();
}//返回的结果是NaN
请大佬帮我看一下,这种错误的原因




