关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
地推
2022-10-20 18:31
采纳率: 58.8%
浏览 2
首页
其他
已结题
为什么requests.get 获取腾讯视频的代码会与urllib.urlopen获取的差很多?
其他
为什么requests.get 获取腾讯视频的源代码会与urllib.urlopen获取的差很多?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
0
条回答
默认
最新
查看更多回答(-1条)
向“C知道”追问
报告相同问题?
提交
关注问题
requests
.get与
urllib
.request.
url
open
的使用
2023-02-15 16:07
需要学习的蓝的博客
requests
.get与
urllib
.request.
url
open
的使用
[Python系列-19]:爬虫 -
urllib
.request.
url
open
()和
urllib
.request.get()的使用区别
2021-08-19 12:42
文火冰糖的硅基工坊的博客
第2章
urllib
.request.
requests
.get() 2.1 功能描述 2.2 函数原型 第1章
urllib
.request.
url
open
1.1 功能描述 打开
URL
网址,
url
参数可以是一个字符串
url
或一个Request对象; 返回http.cli..
requests
.get和
url
open
的比较(通俗易懂)
2021-08-08 17:16
一定会成为大牛的小宋的博客
requests
.get和
url
open
的比较
url
open
详解见:https://blog.csdn.net/qq_41845823/article/details/119465293
requests
.get详解见:https://blog.csdn.net/qq_41845823/article/details/119516178
url
open
简介 ...
urllib
.request.
url
open
详解
2021-08-06 23:32
一定会成为大牛的小宋的博客
Urllib
是python内置的HTTP请求库: ...python2中
urllib
2库中的
很多
方法在python3中被移至
urllib
.request库中。
urllib
.request.
url
open
urllib
.request.
url
open
(
url
, data=None, [timeout, ]*, caf
05.爬虫---
urllib
与
requests
请求实战(GET)
2024-05-27 09:06
小孟技术栈的博客
urllib
能够处理的基本请求包括GET、POST、PUT、DELETE等,同时也支持设置请求头、请求体、处理cookies等高级功能,但其API相对较为底层,使用起来比较繁琐。请求头对爬虫来说,就好像一个面具,去模仿人去浏览网站,...
python3中request.
url
open
()和
requests
.get()方法的区别
2020-09-21 01:35
paigujing的博客
爬虫里面,我们不可避免的要用
urllib
中的
url
open
()和
requests
.get()方法去请求或
获取
一个网页的内容,这里面的区别在于
url
open
打开
URL
网址,
url
参数可以是一个字符串
url
或者是一个Request对象,返回的是...
python中request.
url
open
()和
requests
.get()方法的区别
2019-04-22 14:57
csdn-JAVA-LIFE的博客
爬虫里面,我们不可避免的要用
urllib
中的
url
open
()和
requests
.get()方法去请求或
获取
一个网页的内容,这里面的区别在于
url
open
打开
URL
网址,
url
参数可以是一个字符串
url
或者是一个Request对象,返回的是...
爬虫基础----6.
urllib
与
requests
基础(1)
2022-10-19 21:48
狐狸v糊涂的博客
print(response.getcode()) #
获取
URL
print(response.get
url
()) #
获取
请求头 print(response.getheaders()) # 读取响应 print(response.read().decode('UTF-8')) # 下载数据 保存文件名称为baidu....
用
requests
.get爬取网站时遇到TimeoutError、
urllib
3.exceptions.ConnectTimeoutError等问题
2020-08-02 15:46
学习要深度的博客
今天在爬诗词名句网站上的三国演义内容时,遇到了反爬,采用
requests
.get(
url
=
url
, headers=headers)
会
产生以下报错: Traceback (most recent call last): File "F:\anaconda3\envs\Python3.8\lib\site-packages\...
python网络爬虫
urllib
.request模块get请求示例
2022-01-09 16:18
侯小啾的博客
urllib
.request使用示例 示例 需求:向向百度发请求,
获取
响应,得到html文件 import
urllib
.request response =
urllib
.request.
url
open
('https://www.baidu.com') # 在
url
open
()中传入
url
参数,以
获取
响应对象 ...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已结题
(查看结题原因)
10月20日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
10月20日
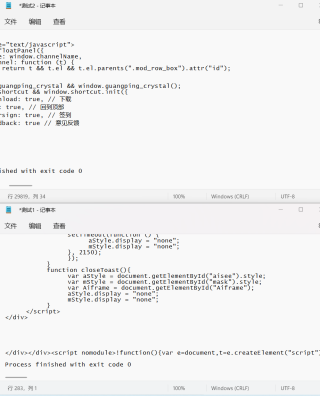
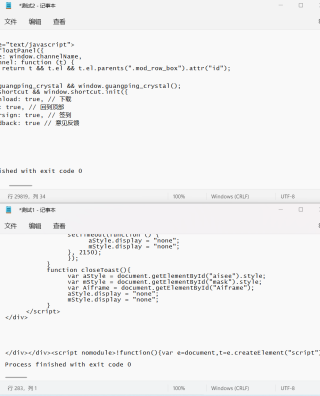

 分享
分享 已结题
(查看结题原因) 10月20日
创建了问题
10月20日
已结题
(查看结题原因) 10月20日
创建了问题
10月20日

