以下这一段,是我进行新闻汽车之家爬取时,需要构建网页,步长为10,即第一页是0,第二页是10,第三页是20,以此类推。我执行以下代码是获取了第一位i,即0,获取了第一页的网址。但是第二页,第三页获取不了 这是为什么啊
import requests
from bs4 import BeautifulSoup
urls=[]
for i in range(0,4,10):
url="https://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=%E6%96%B0%E9%97%BB%E6%B1%BD%E8%BD%A6%E4%B9%8B%E5%AE%B6&cl=2&x_bfe_rqs=032000000000000000000000000000000000000000000008&x_bfe_tjscore=0.080000&tngroupname=organic_news&newVideo=12&goods_entry_switch=1&rsv_dl=news_b_pn&pn={}%22.format(i)
urls.append(url)
print(urls)

爬虫构建网页 获取不了多个网页

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 [小G] 2022-10-23 18:52关注
[小G] 2022-10-23 18:52关注range(0,41,10)分别得到0,10,20,30,40
range三个参数意思分别是:start开始,end结束,step步长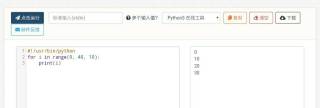 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
- 2026-03-12 14:22本资源包提供了一个完整的Go语言并发编程实战项目,通过构建一个高性能Web爬虫,深入解析Go的并发模型与核心机制。项目源码涵盖goroutine、channel、sync包等关键技术,实现多线程并发抓取、数据解析与存储,并优化...
- 2024-10-04 12:37总体来看,该项目通过提供丰富的源码和文件类型,构建了一个功能全面、支持多语言的网络爬虫系统。这不仅为专业人士提供了强大的数据抓取工具,也为初学者提供了学习和实践Python网络爬虫技术的良好平台。对于那些...
- 2025-07-17 09:39Python编程实现的网络爬虫项目在从网站获取图片方面具有极高的实用价值和广泛的应用前景。通过系统学习和实践,我们可以掌握这项技术,并将其应用于数据采集、图片资源整理、网络分析等多方面,为我们的工作和学习...
- 2024-06-28 16:46Python作为一种强大的编程语言,提供了丰富的库来帮助我们从网页中提取信息,即所谓的网页爬虫。本文将详细介绍如何使用Python创建一个基本的网页爬虫,包括所需的工具、步骤以及一些实用的技巧。 网页爬虫(Web ...
- 2026-03-25 20:26项目包括:并发网页爬虫(Worker Pool模式,使用Goroutine、Channel、WaitGroup)、实时聊天室(Fan-out模式,涉及Select多路复用与Mutex锁管理)、分布式任务队列系统(Context控制,实现超时与优雅关闭)以及高...
- 2024-01-18 10:28这份"python爬虫学习文档"涵盖了多个关键领域,包括爬虫基础、加密算法、并发编程以及安卓逆向,旨在帮助学习者全面掌握爬虫相关的高级技能。 首先,让我们深入探讨**爬虫基础**。爬虫基础是所有爬虫学习者的起点,...
- 2024-10-09 03:42在当今快速发展的IT行业中,多语言编程已经成为一个不可或缺的技能。本项目提供了一个全面的技术参考,集合了多种编程语言和文件类型,以便开发者能够更全面地掌握和应用多语言编程技术。 Python是一种广泛使用的...
- 2022-09-24 05:41标题中的"http_down_image.zip"是一个压缩包文件,其主题涉及到爬虫技术和...同时,这个例子也为更高级的爬虫开发打下了基础,例如,扩展为处理多线程或异步请求,增加日志记录,或者处理更复杂的网页结构和反爬机制。
- 2021-09-10 17:35本主题聚焦于使用MATLAB实现爬虫,以及如何利用这种强大的编程环境来获取和处理网页信息。MATLAB虽然并非传统的网络爬虫开发语言,如Python或Java,但其丰富的数学计算和数据分析功能使得它在特定场景下极具优势。 ...
- 2016-06-14 16:28在IT行业中,网络爬虫是一种自动化程序,用于从互联网上抓取信息,而C#作为.NET框架的主要编程语言,提供了丰富的库和工具来构建这样的应用。本项目名为"C#网页抓取(网络爬虫)的新闻弹窗小工具",其目的是通过C#...
- 没有解决我的问题, 去提问

问题事件
 系统已结题
10月31日
系统已结题
10月31日 已采纳回答
10月23日
已采纳回答
10月23日-
修改了问题
10月23日
-
创建了问题
10月23日