有没有会数据可视化分析的专业人员,搭理我一些笨蛋问题,因为他们给我代码,我可能也不会,因为我就没有学过,我需要你们看着我的代码,然后来给我解决问题
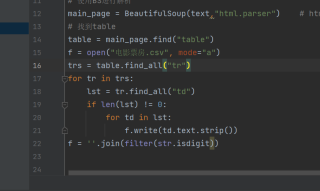

有没有会数据可视化分析的专业人员,搭理我一些笨蛋问题,因为他们给我代码,我可能也不会,因为我就没有学过,我需要你们看着我的代码,然后来给我解决问题
 分享
分享
 关注
关注问题是啥?
分享 系统已结题
11月7日
系统已结题
11月7日 已采纳回答
10月30日
创建了问题
10月28日
已采纳回答
10月30日
创建了问题
10月28日


