数据预处理,在mvn项目下,我对爬下的数据进行预处理,在mvn环境中可以正常执行,也可以获得运算结果,可是打成jar包后,放入centos7 的hadoop集群下执行,就出现错误
用代码块功能插入代码,请勿粘贴截图
package com.position.clean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.lib.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
public class CleanMain {
public static void main(String[] args) throws Exception {
//控制台输出执行日志
BasicConfigurator.configure();//这里不需要返回值
//第一步:初始化Hadoop环境
Configuration conf = new Configuration();
//从虚拟机运行行获取“两个”参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();//通过此方法可以将传入的两个参数转变成一个数组
//判断从crt获得的参数是否是两个参数,如果不是两个参数,则会输出错误并退出程序
if(otherArgs.length !=2){
//此处使用系统内置函数err进行错误报告,执行完成后需要退出系统进程
System.err.print("Usage : wordcount <in> <out>"); //<in>为输入路径 <out>为输出路径
System.exit(2);
}
//第二步:定义一个新的Job,第一个参数是hadoop的配置信息,第二个是job的名字
Job job = new Job(conf,"job");//"job"定义一个job名称,Job被划黑线说明该方法已经过时了,可是方法依然可以使用
//第三步:设置主类
job.setJarByClass(CleanMain.class);//将主类打成jar包
//第四步:设置Mapper类
job.setMapperClass(CleanMapper.class);//将Mapper打成jar包
//设置处理小文件的对象,将文件的输入内容从各个零散的小文件转变成CombineText文件
job.setInputFormatClass(CombineTextInputFormat.class);//由于要处理小文件,CombineTextInputFormat.class此方法有较好的计算特性
//设置n个小文件,其数据总体大小不能够小于2M(2097152)
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
//设置n个小文件,其数据总体大小不能够大于4M(4194304)
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
//第五步:设置job输出数据的key类
job.setOutputKeyClass(Text.class);//key是Text类型
//第六步:设置job输出数据的value类
job.setOutputValueClass(NullWritable.class);//key是NullWritable类型
//第七步:设置输入路径: 即是hdfs上的路径
//FileInputFormat.addInputPath(job, new Path("hdfs://spark02:9000/Jobdata/20200803"));
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//otherArgs[0] 第一个输入的参数
//第八步:设置输出路径:即是本地路径,路径中的两个斜杠(“//”),其中一个/是用来转义字符
//FileOutputFormat.setOutputPath(job, new Path("D:\\software_root\\Hadoop_test_file\\Out"));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//otherArgs[1] 第二个输入的参数
//第九步:退出程序
System.exit(job.waitForCompletion(true)?0:1);
}
}
运行结果及报错内容
4726 [main] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://spark01:8088/proxy/application_1667464489746_0006/
22/11/03 20:39:47 INFO mapreduce.Job: Running job: job_1667464489746_0006
4727 [main] INFO org.apache.hadoop.mapreduce.Job - Running job: job_1667464489746_0006
22/11/03 20:40:28 INFO mapreduce.Job: Job job_1667464489746_0006 running in uber mode : false
45934 [main] INFO org.apache.hadoop.mapreduce.Job - Job job_1667464489746_0006 running in uber mode : false
22/11/03 20:40:28 INFO mapreduce.Job: map 0% reduce 0%
45937 [main] INFO org.apache.hadoop.mapreduce.Job - map 0% reduce 0%
22/11/03 20:40:42 INFO mapreduce.Job: Task Id : attempt_1667464489746_0006_m_000000_0, Status : FAILED
60203 [main] INFO org.apache.hadoop.mapreduce.Job - Task Id : attempt_1667464489746_0006_m_000000_0, Status : FAILED
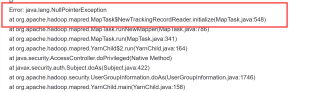
Error: java.lang.NullPointerException
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.initialize(MapTask.java:548)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:786)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
我的解答思路和尝试过的方法
我在mvn环境中可以正常执行,就是使用jar包去执行的时候会报错
hadoop jar clean.jar com.position.clean.CleanMain /Jobdata/20200803/ /Jobdata/output
com.position.clean.CleanMain 是我写好的方法主类
我想要达到的结果
深圳,14-18,绩效奖金-五险一金-专项奖金-交通补助-职位高大上-行业老大,Hadoop-Scala
深圳,15-25,节日礼物-带薪年假-扁平管理-美女多-福利待遇好 发展空间大 上市公司,Hadoop-ETL
上海,10-20,周末双休-年终奖-五险一金-加班补贴,Java-Hadoop
上海,16-25,技能培训-年度旅游-岗位晋升-扁平管理-聚焦政府大数据-助力城市精细化管理,ETL-Hadoop-Spark-Flink
北京,20-30,五险一金-年底双薪,Hadoop-Spark
上海,15-25,技能培训-年度旅游-岗位晋升-五险一金-精英团队-弹性工作-工作氛围好,Hadoop-Spark-Hive-MySQL
广州,12-20,绩效奖金-专项奖金-年底双薪-五险一金-有机会转为联通国企编制,ETL
杭州,20-35,期权激励-住房补贴-全额公积金-午餐补助-高挑战-高待遇-高福利-高成长,Spark-数据仓库-Flink-Hive
杭州,15-30,扁平管理-岗位晋升-五险一金-技能培训-技术驱动-行业前驱-领导好-扁平管理,数据分析
北京,15-30,六险一金-工作居住证-年度旅游-定期体检-17薪-午休两小时,Scala-Java
上海,25-35,节日礼物-岗位晋升-五险一金-午餐补助-绩效奖金- 带薪年假-午餐补助-岗位晋升,