
在爬一个金融类网站的数据的时候发现jousp获取的html里面居然有个div是空的

然而在chrome的后台看,我需要的数据都在这个div里,求大神解释这是什么情况!
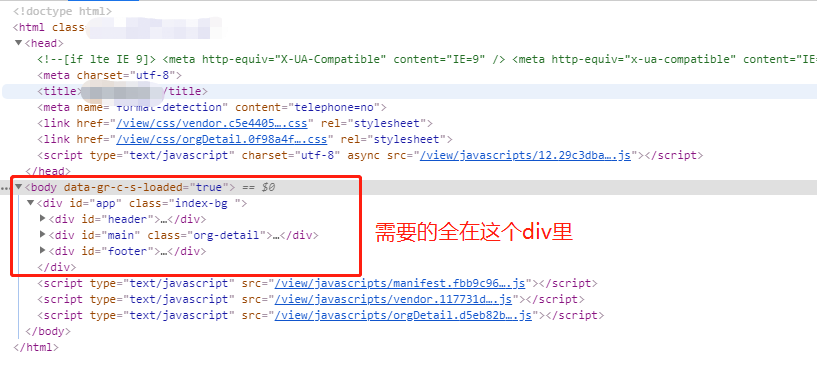
CSDN上的这个帖子https://bbs.csdn.net/topics/392361731 的问题是一样的,但是看了底下的回答实在是太模糊了,没有提出解决方法
附上源码:
import java.io.IOException;
import java.util.Map;
import org.jsoup.*;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
class Main {
private String loginURL =
private String WebURL =
private Map<String, String> loginCookies = null;
private static Document document = null;
public static void main(String[] args) {
Main This = new Main();
try {
This.bypassLogin();
This.getDocument();
}catch (IOException e){
System.out.println(e);
}
if(document!=null) {
System.out.println("Document accessed!");
System.out.println(document.toString());
This.getContent();
}else{
System.out.println("Document not accessed!");
}
System.out.println("Program Ended");
}
private void getContent(){
Element content = document.select("span.stock-yellow").first();
System.out.println(content.toString());
}
private void getDocument() throws IOException{
if (loginCookies!=null){
document = Jsoup.connect(WebURL)
.cookies(loginCookies)
.userAgent("Mozilla/5.0 (Windows; U; WindowsNT 5.1; en-US; rv1.8.1.6) Gecko/20070725 Firefox/2.0.0.6")
.referrer("www.google.com")
//.ignoreHttpErrors(true)
.maxBodySize(0)
.get();
}else{
System.out.println("Login Cookies is NULL");
}
}
private void bypassLogin() throws IOException {
Connection webConnection = Jsoup.connect(loginURL);
webConnection.header("Accept", "*/*").header("Accept-encoding", "gzip,deflate,br");
webConnection.header("Accept-language", "en,zh-CN,q=0.9,zh;q=0.8").header("Connection", "keep-alive");
webConnection.header("Content-length", "526").header("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
webConnection.header("DNT", "1").header("HOST", "www.12345fund.com");
webConnection.header("Origin", "/*马赛克*/").header("Referer", "www.google.com");
webConnection.header("User-Agent", "ozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36");
webConnection.header("X-Requested-With", "XMLHttpRequest");
webConnection.data("account_name", "/*马赛克*/")
.data("autologin", "1")
.data("terminal_id", "/*马赛克*/")
.data("is_phone", "false")
.data("browser", "Chrome")
.data("browser_code", "Mozilla")
.data("browser_name", "Netscape")
.data("browser_version", "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36")
.data("browser_hardware_platform", "Win32")
.data("browser_user_agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36")
.data("passwordmd5", "/*马赛克*/");
Connection.Response res = webConnection.ignoreContentType(true).method(Connection.Method.POST).execute();
loginCookies = res.cookies();
}
}





