
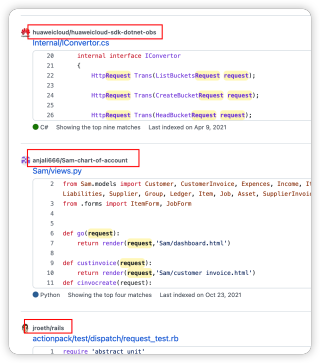
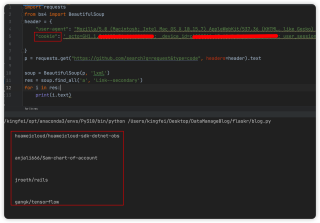
用python爬github的代码,到了从html文件中抽取那了,用beautifulsoup来解析,然后使用soup.find函数,想要获得作者名和库名这个内容,尝试了一下这个link--secondary,但是不对,有人知道这里应该填什么吗?
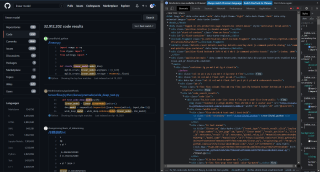


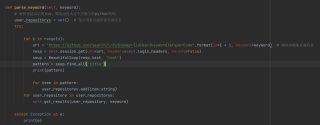

用python爬github的代码,到了从html文件中抽取那了,用beautifulsoup来解析,然后使用soup.find函数,想要获得作者名和库名这个内容,尝试了一下这个link--secondary,但是不对,有人知道这里应该填什么吗?
 分享
分享

分享 系统已结题
11月21日
系统已结题
11月21日 已采纳回答
11月13日
赞助了问题酬金15元
11月13日
修改了问题
11月13日
已采纳回答
11月13日
赞助了问题酬金15元
11月13日
修改了问题
11月13日


