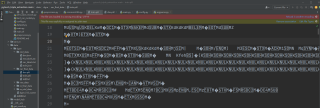
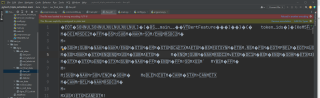
运行preprocess.py文件后,这两个文件变成乱码。
import os
import json
import logging
from transformers import BertTokenizer
try:
from utils import cutSentences, commonUtils
import config
except Exception as e:
from .utils import cutSentences, commonUtils
from . import config
else:
from utils import cutSentences, commonUtils
import config
logger = logging.getLogger(name)
class InputExample:
def init(self, set_type, text, subject_labels=None, object_labels=None):
self.set_type = set_type
self.text = text
self.subject_labels = subject_labels
self.object_labels = object_labels
class BaseFeature:
def init(self, token_ids, attention_masks, token_type_ids):
# BERT 输入
self.token_ids = token_ids
self.attention_masks = attention_masks
self.token_type_ids = token_type_ids
class BertFeature(BaseFeature):
def init(self, token_ids, attention_masks, token_type_ids, labels=None):
super(BertFeature, self).init(
token_ids=token_ids,
attention_masks=attention_masks,
token_type_ids=token_type_ids)
# labels
self.labels = labels
class NerProcessor:
def init(self, cut_sent=True, cut_sent_len=256):
self.cut_sent = cut_sent
self.cut_sent_len = cut_sent_len
@staticmethod
def read_json(file_path):
with open(file_path, encoding='utf-8') as f:
raw_examples = json.load(f)
return raw_examples
def get_examples(self, raw_examples, set_type):
examples = []
# 这里是从json数据中的字典中获取
for i, item in enumerate(raw_examples):
# print(i,item)
text = item['text']
if self.cut_sent:
sentences = cutSentences.cut_sent_for_bert(text, self.cut_sent_len)
start_index = 0
for sent in sentences:
labels = cutSentences.refactor_labels(sent, item['labels'], start_index)
start_index += len(sent)
examples.append(InputExample(set_type=set_type,
text=sent,
labels=labels))
else:
subject_labels = item['subject_labels']
object_labels = item['object_labels']
if len(subject_labels) != 0:
subject_labels = [('subject',label[1],label[2]) for label in subject_labels]
if len(object_labels) != 0:
object_labels = [('object',label[1],label[2]) for label in object_labels]
examples.append(InputExample(set_type=set_type,
text=text,
subject_labels=subject_labels,
object_labels=object_labels))
return examples
def convert_bert_example(ex_idx, example: InputExample, tokenizer: BertTokenizer,
max_seq_len, nerlabel2id, ent_labels):
set_type = example.set_type
raw_text = example.text
subject_entities = example.subject_labels
object_entities = example.object_labels
entities = subject_entities + object_entities
# 文本元组
callback_info = (raw_text,)
# 标签字典
callback_labels = {x: [] for x in ent_labels}
# _label:实体类别 实体名 实体起始位置
for _label in entities:
# print(_label)
callback_labels[_label[0]].append((_label[0], _label[1]))
callback_info += (callback_labels,)
# 序列标注任务 BERT 分词器可能会导致标注偏
# tokens = commonUtils.fine_grade_tokenize(raw_text, tokenizer)
tokens = [i for i in raw_text]
assert len(tokens) == len(raw_text)
label_ids = None
# information for dev callback
# ========================
label_ids = [0] * len(tokens)
# tag labels ent ex. (T1, DRUG_DOSAGE, 447, 450, 小蜜丸)
for ent in entities:
# ent: ('PER', '陈元', 0)
ent_type = ent[0] # 类别
ent_start = ent[-1] # 起始位置
ent_end = ent_start + len(ent[1]) - 1
if ent_start == ent_end:
label_ids[ent_start] = nerlabel2id['B-' + ent_type]
else:
try:
label_ids[ent_start] = nerlabel2id['B-' + ent_type]
label_ids[ent_end] = nerlabel2id['I-' + ent_type]
for i in range(ent_start + 1, ent_end):
label_ids[i] = nerlabel2id['I-' + ent_type]
except Exception as e:
print(ent)
print(tokens)
import sys
sys.exit(0)
if len(label_ids) > max_seq_len - 2:
label_ids = label_ids[:max_seq_len - 2]
label_ids = [0] + label_ids + [0]
# pad
if len(label_ids) < max_seq_len:
pad_length = max_seq_len - len(label_ids)
label_ids = label_ids + [0] * pad_length # CLS SEP PAD label都为O
assert len(label_ids) == max_seq_len, f'{len(label_ids)}'
# ========================
encode_dict = tokenizer.encode_plus(text=tokens,
max_length=max_seq_len,
padding='max_length',
truncation='longest_first',
return_token_type_ids=True,
return_attention_mask=True)
tokens = ['[CLS]'] + tokens + ['[SEP]']
token_ids = encode_dict['input_ids']
attention_masks = encode_dict['attention_mask']
token_type_ids = encode_dict['token_type_ids']
if ex_idx < 3:
logger.info(f"*** {set_type}_example-{ex_idx} ***")
print(tokenizer.decode(token_ids[:len(raw_text)]))
logger.info(f'text: {" ".join(tokens)}')
logger.info(f"token_ids: {token_ids}")
logger.info(f"attention_masks: {attention_masks}")
logger.info(f"token_type_ids: {token_type_ids}")
logger.info(f"labels: {label_ids}")
logger.info('length: ' + str(len(token_ids)))
# for word, token, attn, label in zip(tokens, token_ids, attention_masks, label_ids):
# print(word + ' ' + str(token) + ' ' + str(attn) + ' ' + str(label))
feature = BertFeature(
# bert inputs
token_ids=token_ids,
attention_masks=attention_masks,
token_type_ids=token_type_ids,
labels=label_ids,
)
return feature, callback_info
def convert_examples_to_features(examples, max_seq_len, bert_dir, nerlabel2id, ent_labels):
tokenizer = BertTokenizer(os.path.join(bert_dir, 'vocab.txt'))
features = []
callback_info = []
logger.info(f'Convert {len(examples)} examples to features')
for i, example in enumerate(examples):
"""
subject_entities = example.subject_labels
object_entities = example.object_labels
entities = subject_entities + object_entities
flag = False
for ent in entities:
start_id = ent[1]
end_id = len(ent[0]) + ent[1]
if start_id >= max_seq_len - 2 or end_id >= max_seq_len - 2:
flag = True
break
if flag:
continue
"""
feature, tmp_callback = convert_bert_example(
ex_idx=i,
example=example,
max_seq_len=max_seq_len,
nerlabel2id=nerlabel2id,
tokenizer=tokenizer,
ent_labels=ent_labels,
)
if feature is None:
continue
features.append(feature)
callback_info.append(tmp_callback)
logger.info(f'Build {len(features)} features')
out = (features,)
if not len(callback_info):
return out
out += (callback_info,)
return out
def get_data(processor, raw_data_path, json_file, mode, nerlabel2id, ent_slabels, args):
raw_examples = processor.read_json(os.path.join(raw_data_path, json_file))
examples = processor.get_examples(raw_examples, mode)
data = convert_examples_to_features(examples, args.max_seq_len, args.bert_dir, nerlabel2id, ent_labels)
save_path = os.path.join(args.data_dir, 'ner_final_data')
if not os.path.exists(save_path):
os.makedirs(save_path)
commonUtils.save_pkl(save_path, data, mode)
return data
def save_file(filename, data, id2nerlabel):
features, callback_info = data
file = open(filename,'w',encoding='utf-8')
for feature,tmp_callback in zip(features, callback_info):
text, gt_entities = tmp_callback
for word, label in zip(text, feature.labels[1:len(text)+1]):
file.write(word + ' ' + id2nerlabel[label] + '\n')
file.write('\n')
file.close()
if name == 'main':
dataset = "dgre"
args = config.Args().get_parser()
args.bert_dir = '../model_hub/chinese-roberta-wwm-ext/'
commonUtils.set_logger(os.path.join(args.log_dir, 'preprocess.log'))
if dataset == "dgre":
args.data_dir = '../data/dgre/'
args.max_seq_len = 512
elif dataset == "duie":
args.data_dir = '../data/'
args.max_seq_len = 300
mid_data_path = os.path.join(args.data_dir, 'mid_data')
# 真实标签
ent_labels_path = mid_data_path + '/ent_labels.txt'
# 序列标注标签B I O
ner_labels_path = mid_data_path + '/ner_labels.txt'
with open(ent_labels_path, 'r',encoding='utf-8') as fp:
ent_labels = fp.read().strip().split('\n')
entlabel2id = {}
id2entlabel = {}
for i,j in enumerate(ent_labels):
entlabel2id[j] = i
id2entlabel[i] = j
nerlabel2id = {}
id2nerlabel = {}
with open(ner_labels_path,'r',encoding='utf-8') as fp:
ner_labels = fp.read().strip().split('\n')
for i,j in enumerate(ner_labels):
nerlabel2id[j] = i
id2nerlabel[i] = j
processor = NerProcessor(cut_sent=False, cut_sent_len=args.max_seq_len)
train_data = get_data(processor, mid_data_path, "train.json", "train", nerlabel2id, ent_labels, args)
save_file(os.path.join(args.data_dir,"{}_{}_cut.txt".format(dataset, args.max_seq_len)), train_data, id2nerlabel)
dev_data = get_data(processor, mid_data_path, "dev.json", "dev", nerlabel2id, ent_labels, args)
乱码文件的截图