
用的pandas标准库,遍历xlsx文件时,“NA”字符串似乎识别不出来?小写的“na”都可以,这是什么原因,怎么解决呀
下面是代码和部分excel表
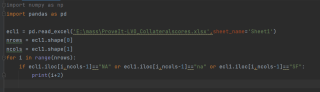


用的pandas标准库,遍历xlsx文件时,“NA”字符串似乎识别不出来?小写的“na”都可以,这是什么原因,怎么解决呀
下面是代码和部分excel表
 分享
分享
pandas 会将NA解释为NaN,你可以添加参数避免这种情况
pd.read_excel("1.xlsx", keep_default_na=False)
 系统已结题
11月29日
系统已结题
11月29日 已采纳回答
11月21日
创建了问题
11月21日
已采纳回答
11月21日
创建了问题
11月21日




