python有关BeautifulSoup的问题,不知道是什么问题报错:
这是问题(提取网页新闻信息的http://money.163.com/special/pinglun/):
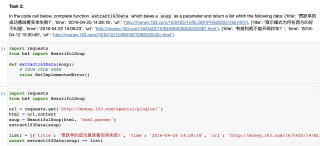
这是我的解决方法:
这是我的方法报错的地方:


python有关BeautifulSoup的问题,不知道是什么问题报错:
这是问题(提取网页新闻信息的http://money.163.com/special/pinglun/):
这是我的解决方法:
这是我的方法报错的地方:
 分享
分享
这句有问题
a=soup.select('.list_item')
要限制只查询新闻的h2,要不页面上有很多h2标签,有些h2标签下没有a会出错,find后返回none会出错
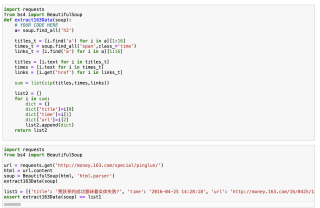
完整代码如下,改了下逻辑
from bs4 import BeautifulSoup
import requests
def extract163Data(soup):
#下面直接获取新闻容器
items=soup.select('.list_item')
titles=[i.find('a') for i in items]
times=[i.find('span',class_='time').text for i in items]
links=[i.find('a').get('href') for i in items]
lst=[]
for i in range(len(titles)):
lst.append({'title':titles[i],'time':times[i],'url':links[i]})
if i>1:#取前3条,取全部注释这里2句
break
return lst
text=requests.get('http://money.163.com/special/pinglun/').content
soup=BeautifulSoup(text,'html.parser')
print(extract163Data(soup))
 系统已结题
12月3日
系统已结题
12月3日 已采纳回答
11月25日
创建了问题
11月25日
已采纳回答
11月25日
创建了问题
11月25日


