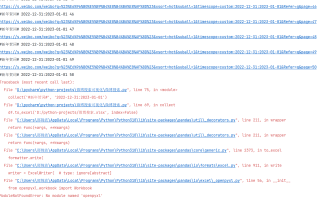
问题:代码运行后表格输出不了
# coding=gbk
# -*- coding:uft-8 -*-
# 微博搜索
import requests
from lxml import etree
import time
from urllib import parse
import pandas as pd
def collect(k, da):
resLs = []
for page in range(50):
time.sleep(2)
page += 1
url = f'https://s.weibo.com/weibo?q={parse.quote(k)}&xsort=hot&suball=1×cope=custom:{da}&Refer=g&page={page}'
print(url)
print(k, da, page)
headers = {
'Cookie': ck,
'User-Agent': ua,
'Referer': url
}
while True:
try:
res = requests.get(url=url, headers=headers, timeout=(5, 5)).content.decode('utf-8', errors='ignore')
break
except:
time.sleep(2)
if f'抱歉,未找到“{k}”相关结果。
' in res:
break
tree = etree.HTML(res)
for li in tree.xpath('//div[@action-type="feed_list_item"]'):
name = li.xpath('.//a[@class="name"]/text()')[0]
date = li.xpath('.//p[@class="from"]/a/text()')[0].strip()
cbox = li.xpath('.//p[@node-type="feed_list_content_full"]')
cbox = li.xpath('.//p[@node-type="feed_list_content"]')[0] if not cbox else cbox[0]
cont = '\n'.join(cbox.xpath('./text()')).strip()
tran = li.xpath('.//div[@class="card-act"]/ul/li[1]/a//text()')[1].strip()
try:
tran = eval(tran)
except:
tran = 0
comm = li.xpath('.//div[@class="card-act"]/ul/li[2]/a//text()')[0].strip()
try:
comm = eval(comm)
except:
comm = 0
like = li.xpath('.//div[@class="card-act"]/ul/li[3]/a//text()')[0].strip()
try:
like = eval(like)
except:
like = 0
ID = li.xpath('./@mid')[0]
dic = {
'昵称': name,
'时间': date,
'内容': cont,
'转发': tran,
'评论': comm,
'点赞': like,
'链接': f'https://m.weibo.cn/detail/{ID}',
'ID': ID
}
resLs.append(dic)
print(dic)
df = pd.DataFrame(resLs)
df.to_excel('D:/python-projects/微博搜索.xlsx', index=False)
if __name__ == '__main__':
ck = 'SINAGLOBAL=4454308048539.024.1643708323694; UOR=,,www.baidu.com; PC_TOKEN=a92ce85638; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFM8PQNOuSqoMODXmj7s6._5JpX5KMhUgL.FoMceh5Xe024SK52dJLoI0qLxK-L1K.L1-eLxK-L1K-LBKqLxK-L1K.L1-eLxK-L1K-LBKqLxK-L1KnL1--LxKMLB.zLB.qt; ALF=1686135504; SSOLoginState=1654599505; SCF=AsEb2zshx_FnkEijdlcLhh6otJzpQ8lkHk85ZOPwgAo2aHvNLE4plpr8df82bpCcn7X4xaDNKey82rxt5vxU7ao.; SUB=_2A25Pm18BDeRhGeFI61IV8y_FzjyIHXVs0TfJrDV8PUNbmtAfLUvTkW9NfWwekjxblRZSYlCn6pgNSJyzae4TacWZ; XSRF-TOKEN=j-jv-3EZdbv8diWwSDRg6Ala; WBPSESS=Ml88U9RPTFLzaBK37303P30soCZeyxsaXD-HRJbXS-Gosuo1qU_H6W_kmZRpTh27MhD6E3SIXJ_wbKp5CF_WExjeXE7lBgmyjKqeNr33sxzvpIW7j9bQlB_OsVdOEA9rcAwOvwUIe8jl2UwcyPTBig==; _s_tentry=weibo.com; Apache=9328862948114.203.1654599516792; ULV=1654599516822:24:2:1:9328862948114.203.1654599516792:1654329837929'
ua = 'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/91.0.4472.106Safari/537.36'
collect('#新年贺词#', '2022-12-31:2023-01-01')
结果显示