
文本中包含两种日期格式数据:
某年某月某日
某月某日
(其中月和日前可能是1位或者2位)
现在需要用正则提取两种日期格式字符串。
我的思路是某年出现0或1次,后面的出现1次。
我写的代码:
text = "2022年1月2日 1月3日"
data=re.findall("(\d{4}年)?\d{1,2}月\d{1,2}日",text)
运行后的结果:
['2022年', '']
请问如何改进?

文本中包含两种日期格式数据:
某年某月某日
某月某日
(其中月和日前可能是1位或者2位)
现在需要用正则提取两种日期格式字符串。
我的思路是某年出现0或1次,后面的出现1次。
我写的代码:
text = "2022年1月2日 1月3日"
data=re.findall("(\d{4}年)?\d{1,2}月\d{1,2}日",text)
运行后的结果:
['2022年', '']
请问如何改进?
 分享
分享
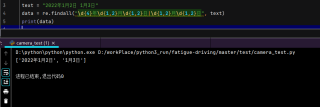
text = "2022年1月2日 1月3日"
data = re.findall("\d{4}年\d{1,2}月\d{1,2}日|\d{1,2}月\d{1,2}日", text)
print(data)
望采纳!!!
分享 系统已结题
1月22日
系统已结题
1月22日 已采纳回答
1月14日
创建了问题
1月8日
已采纳回答
1月14日
创建了问题
1月8日


