

问题遇到的现象和发生背景
遇到的现象和发生背景,请写出第一个错误信息
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
运行结果及详细报错内容
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
从一些txt文件中批量提取目标数字和英文,一起输出到excel文件中。
这些txt文件是多个样本网页的txt格式,因此内容类似,比如这些txt中均含有age单词且都在同一行。
①提取txt中含age:X行中的x数字。age作为输出excel文件中的第一列表头,这些txt的文件所有含的xx数字对应在下排列。 txt文件中的该行如图片所示,所有txt只有这行含age且在同一行,(注意排除nameage这种掺杂age的单词)。默认行的序数已知,比如都在第五行。
②提取txt中的phenotyoe:x中的x单词,如①描述,和①要提取的在同一行。将phenotype作为输出excel文件中的第二列表头,这些txt中所有包含的单词对应在下排列。默认行数已知比如都在第五行。
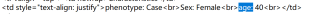
所有txt文件在同一目录下。
试了一天了总是试不出来答案,而且输出excel中很多乱码。
这些txt文件是来自一些临床数据样本网站,所以内容类似。
我想达到的效果是比如现在有两个txt文件,两个内容如图:

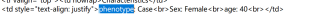
则输出excel文件:
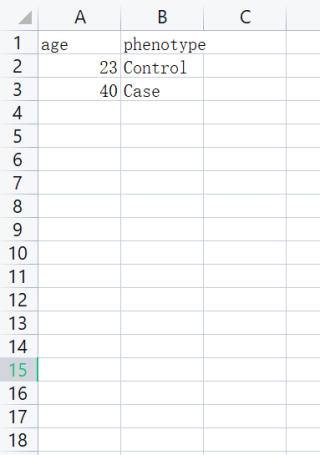
主要就是想把所有文件中的age和phenotype 及其对应:后的整合起来在excel,可以方便我统计数据。
tips:不知道这个条件有没有用,在txt中搜索的话 age:是只有一个,只在指定行的。phenotype: 也是。
```python
import pandas as pd
import numpy as np
import os
os.getcwd() #获取当前工作路径,查看是否是自己的目标路径
os.chdir('/Users/Heihei/Desktop/EX2data/data') #如果不是,改到目标路径
path = '/Users/Heihei/Desktop/EX2data/data'
os.listdir(path) #查看目标路径下有哪些数据
```







