想问一下,想爬取这样的数据到hadoop集群上,然后通过idea的springboot项目连接数据库,获取数据进行可视化。请问应该选择什么数据库安装到集群上进行后续操作呀? mysql吗?还是hive?
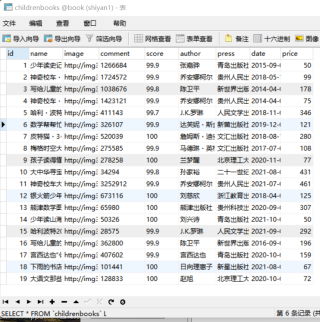

想问一下,想爬取这样的数据到hadoop集群上,然后通过idea的springboot项目连接数据库,获取数据进行可视化。请问应该选择什么数据库安装到集群上进行后续操作呀? mysql吗?还是hive?
 分享
分享
可以考虑Kylin或者Presto
也可以把Hive处理好的结果同步到Mysql里
直接连Hive太慢了
分享 已结题
(查看结题原因) 1月17日
已采纳回答
1月17日
创建了问题
1月13日
已结题
(查看结题原因) 1月17日
已采纳回答
1月17日
创建了问题
1月13日


