
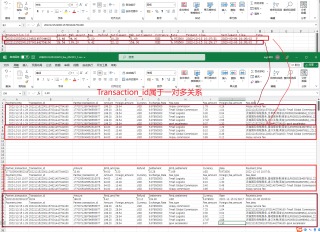
我有2个excel文件,A文件是订单金额信息,B文件是手续费信息,
两个文件都可以用“Transaction_id”来进行一对多进匹配,达到紫色的效果。
这种效果应该不叫合并,所以感觉不是用merge,不知道这种操作叫什么,看了一下groupby,好像也不是。

我有2个excel文件,A文件是订单金额信息,B文件是手续费信息,
两个文件都可以用“Transaction_id”来进行一对多进匹配,达到紫色的效果。
这种效果应该不叫合并,所以感觉不是用merge,不知道这种操作叫什么,看了一下groupby,好像也不是。
 分享
分享
两个dateframe A先根据这个id使用groupby或者筛选到对应的B数据列,然后合并concat操作。需要代码的话,我给你写。采纳下就行。
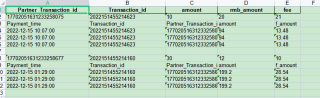
最终效果:
import pandas as pd
# 读取Excel文件
df_a = pd.read_excel('A.xls',dtype=str)
df_b = pd.read_excel('B.xls',dtype=str)
#
df_result = pd.DataFrame()
for i in range(len(df_a)):
transaction_id = df_a.iloc[i]['Transaction_id']
df = df_b[df_b['Transaction_id']==transaction_id] #按transaction_id查找B表的数据
#合并数据
#当前行数据
df_current = df_a.iloc[i].to_frame().T
#获取Partner_Transaction_id列
coumn = pd.DataFrame([df.iloc[0]['Partner_Transaction_id']],columns=['Partner_Transaction_id'],index=[i])
# 增加一列Partner_Transaction_id
df_current = pd.concat([coumn,df_current],axis=1,)
df_result = pd.concat([df_result,df_current])
#增加一行(把B表符合条件的表头作为一行)
row= pd.DataFrame([df.columns.tolist()],columns=df_result.columns)
df_result = pd.concat([df_result,row])
#把B中符合条件的行都添加进来
for j in range(len(df)):
row = pd.DataFrame([df.iloc[j].tolist()], columns=df_result.columns)
df_result = pd.concat([df_result, row],ignore_index=True)
# 每2个记录之间添加一个空行,为了美观
row = pd.DataFrame([["" for a in range(len(df_current.columns))]], columns=df_current.columns)
df_result = pd.concat([df_result, row], ignore_index=True)
# 将结果保存到Excel文件 追加保存
df_result.to_excel('result_ab.xls',index=False)
 系统已结题
2月24日
系统已结题
2月24日 已采纳回答
2月16日
修改了问题
2月15日
创建了问题
2月15日
已采纳回答
2月16日
修改了问题
2月15日
创建了问题
2月15日


