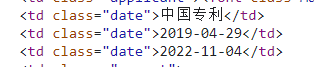
java爬虫,解析html数据后,使用element.getElementsByClass(" ").text()拿去对应的class名的数据时发现有三个数据的class名一样
报错msg: "Text '中国专利 2019-06-25 2022-11-25' could not be parsed at index 0
idea,语言是springboot
Document parse = Jsoup.parse(pantenHtml );
Elements tr = parse.getElementsByClass("result-table-list").first().getElementsByTag("tr");
tr.remove(0);
for (Element element : tr) {
String date1 = element.getElementsByClass("date").text();
String date2 = element.getElementsByClass("date").text();
String date3 = element.getElementsByClass("date").text();
}
html图片: