学习python编写了爬小说的爬虫,执行得到的内容是对的,就是只要爬几十章后就会报这个错误
怎么修改才能执行完?求解惑
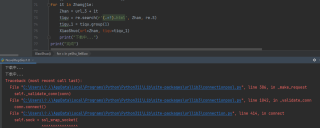

学习python编写了爬小说的爬虫,执行得到的内容是对的,就是只要爬几十章后就会报这个错误
怎么修改才能执行完?求解惑
 分享
分享
根据截图显示的错误信息,可能是由于程序访问网站过于频繁导致被封禁了IP地址,需要等待一段时间才能继续访问。
为了解决这个问题,可以考虑以下方法:
减缓爬取速度:通过在请求头中设置User-Agent和Referer等信息,模拟人类访问网站的行为,降低爬取速度,避免过度频繁地访问网站。
使用代理IP:通过使用代理IP,可以隐蔽真实IP地址,避免被网站封禁。可以在爬虫程序中设置代理IP池,并定时更换代理IP。
添加异常处理机制:在爬虫程序中添加异常处理机制,遇到访问失败或被封禁的情况时,可以自动停止爬虫程序,并等待一段时间后再次尝试访问。
需要注意的是,爬虫行为可能会违反某些网站的服务协议,如果不慎触犯法律或道德规范,可能会面临法律风险或道德谴责。因此,在进行爬虫开发时,需要遵守相关法律法规和道德准则,并尊重网站的服务协议。
分享 系统已结题
3月2日
系统已结题
3月2日 已采纳回答
2月22日
创建了问题
2月19日
已采纳回答
2月22日
创建了问题
2月19日

