

使用hdf5存文件的速度比使用csv存文件的速度还慢是怎么回事?
数据量:2000000
下图是使用hdf5存数据的时间
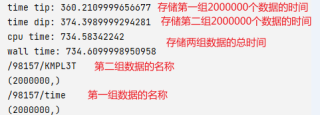
下图是使用csv在相同配置下存相同数据的时间
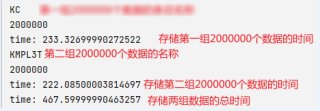
hdf5代码如下:
#2、信号列表
signal=[]
for i in range (3,10):
signal.append('KMPL' + str(i) + 'T')
for i in range (3,5):
signal.append('CMPL' + str(i) + 'T')
for i in range (6,10):
signal.append('CMPL' + str(i) + 'T')
for i in range(2, 9):
signal.append('KMPH' + str(i) + 'T')
for i in range(2, 9):
signal.append('CMPH' + str(i) + 'T')
for i in range(23,26):
signal.append('SXR' + str(i) + 'D')
print(len(signal))
#3、存储数据,存储成HDF5格式
t0=time.time()
t1= time.perf_counter()
pretip = list(east.get('dim_of(\\' + signal[0] + ')'))
tip = pretip[1400000:]
print(tip[0:3])
f=h5py.File(r"..\Data\Raw Data\98157.hdf5", 'w')
#创建一个名字为炮号的组
g=f.create_group("98157")
#在这个组里面分别创建name为time、信号名的数据集并赋值。
g["time"]=tip
t2=time.time()
print("time tip:", t2 - t0)
for i in range(0, 1):
predip = list(east.get('\\' + signal[i]))
dip = predip[len(predip) - len(tip):]
g[signal[i]]=dip
t=time.time()
print("time dip:", t - t2)
t4=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t4-t0)
for key in g.keys():
print(g[key].name)
print(g[key].shape)
f.close()
csv代码如下:
# 信号名列表
#K段、C段
signal200=[]
for i in range (1,11):
signal200.append('KMPL' + str(i) + 'T')
for i in range (1,11):
signal200.append('CMPL' + str(i) + 'T')
for i in range(1, 9):
signal200.append('KMPH' + str(i) + 'T')
for i in range(1, 9):
signal200.append('CMPH' + str(i) + 'T')
def downloadDataKC(shotNumber):
#K段、C段
print("KC")
f = open(r"..\Data\Raw Data\98157.csv", 'w', newline='', encoding='utf-8-sig')
csv_write = csv.writer(f)
# 获取信号时间大于0的数据,存入csv文件
pretip = list(east.get('dim_of(\\' + signal200[0] + ')')) # SXR信号虽然在UDA上比K/CMPH/L大是250khz,但是从同一棵树上抓下来的时间数据和CMPL这些的时间数据一样,所以就算成一样的时间了
tip = pretip[1400000:]
print(len(tip))
csv_write.writerow(tip)
t2=time.time()
print("time:",t2-t1)
# 释放内存
del pretip
# 获取信号强度数据(对应的时刻大于0),存入csv文件
for i in range(2, 3):
predip = list(east.get('\\' + signal200[i]))
dip = predip[len(predip) - len(tip):]
print(signal200[i])
print(len(dip))
# 将数据写入文件
csv_write.writerow(dip)
# 释放内存
del predip, dip
t3=time.time()
print("time:",t3-t2)
# 关闭文件
f.close()
# 释放内存
del tip
gc.collect()
if __name__=='__main__':
print(98157)
east.openTree(mdsTree, 98157)
t1=time.time()
downloadDataKC(98157)
t4 = time.time()
print("time:",t4-t1)








