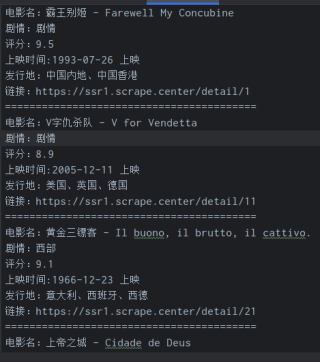
python爬虫,爬取的数据异常,只提取了每一页的第一个内容
import requests
from lxml import etree
def get_data(page):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/109.0.0.0 Safari/537.36'}
res = requests.get('https://ssr1.scrape.center/page/' + str(page), headers=header)
return res.content
def html_data(respon):
html = etree.HTML(respon)
titles = html.xpath('//div[2]/a/h2/text()')
liebies = html.xpath('//div/div/div[2]/div[1]/button/span/text()')
pingfens = html.xpath('//div/div/div[3]/p[1]/text()')
shijians = html.xpath('//div/div[2]/div[3]/span/text()')
lianjies = html.xpath('//div/div/div[2]/a/@href')
chandis = html.xpath('//div/div/div[2]/div[2]/*/text()')
for title, liebie, pingfen, shijian, lianjie, \
chandi in zip(titles, liebies, pingfens, shijians, lianjies, chandis):
pingfen=pingfen.strip()
return f'电影名:{title}\n剧情:{liebie}\n评分:{pingfen}\n上映时间:{shijian}\n发行地:{chandi}\n链接:https://ssr1.scrape.center{lianjie}\n=========================================\n'
def save_data(foods):
f = open('foods.txt', 'a', encoding='utf-8')
f.write(str(foods))
if __name__ == '__main__':
for i in range(1, 11):
page = i
respon = get_data(page)
foods = html_data(respon)
html_data(respon)
save_data(foods)
print(f'---正在保存第{i}页---')