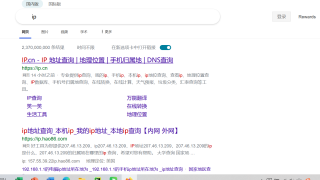
用代理池爬取数据正常爬取到,单单用一个代理爬取则全是广告
一个代理爬取
import urllib.request
url = 'https://www.baidu.com/s?wd=ip'
header = {
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
#代理IP
proxies = {
'http':'111.225.153.46:8089'
}
request = urllib.request.Request(url=url,headers=header)
#handler处理器
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
respone = opener.open(request)
content = respone.read().decode('utf-8')
with open(file='ipp.html',mode='w',encoding='utf-8') as fp:
fp.write(content)
结果
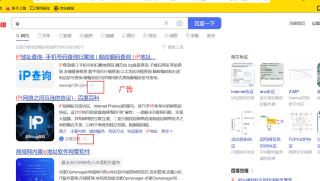
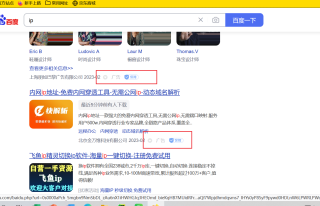
代理池
import urllib.request
import random
url = 'https://cn.bing.com/search?q=ip'
header = {
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
#代理池
proxies_pool = [
{'http':'211.97.2.196:9002'},
{'http':'111.225.153.46:8089'}
]
request = urllib.request.Request(url=url,headers=header)
#从代理池里面随机抽取一个代理IP,我是选择跟上面一个代理IP一样的代理IP结果作为比较的
#即 'http':'111.225.153.46:8089'
proxies = random.choice(proxies_pool)
print(proxies)
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
respone = opener.open(request)
content = respone.read().decode('utf-8')
with open(file='ip_pool.html',mode='w',encoding='utf-8') as fp:
fp.write(content)
结果